一眼看懂
封面预览
探索以视频作为主要模态构建机器人基础模型的新范式,替代传统的视觉-语言-动作(VLA)方法
- 探索以视频作为主要模态构建机器人基础模型的新范式,替代传统的视觉-语言-动作(VLA)方法
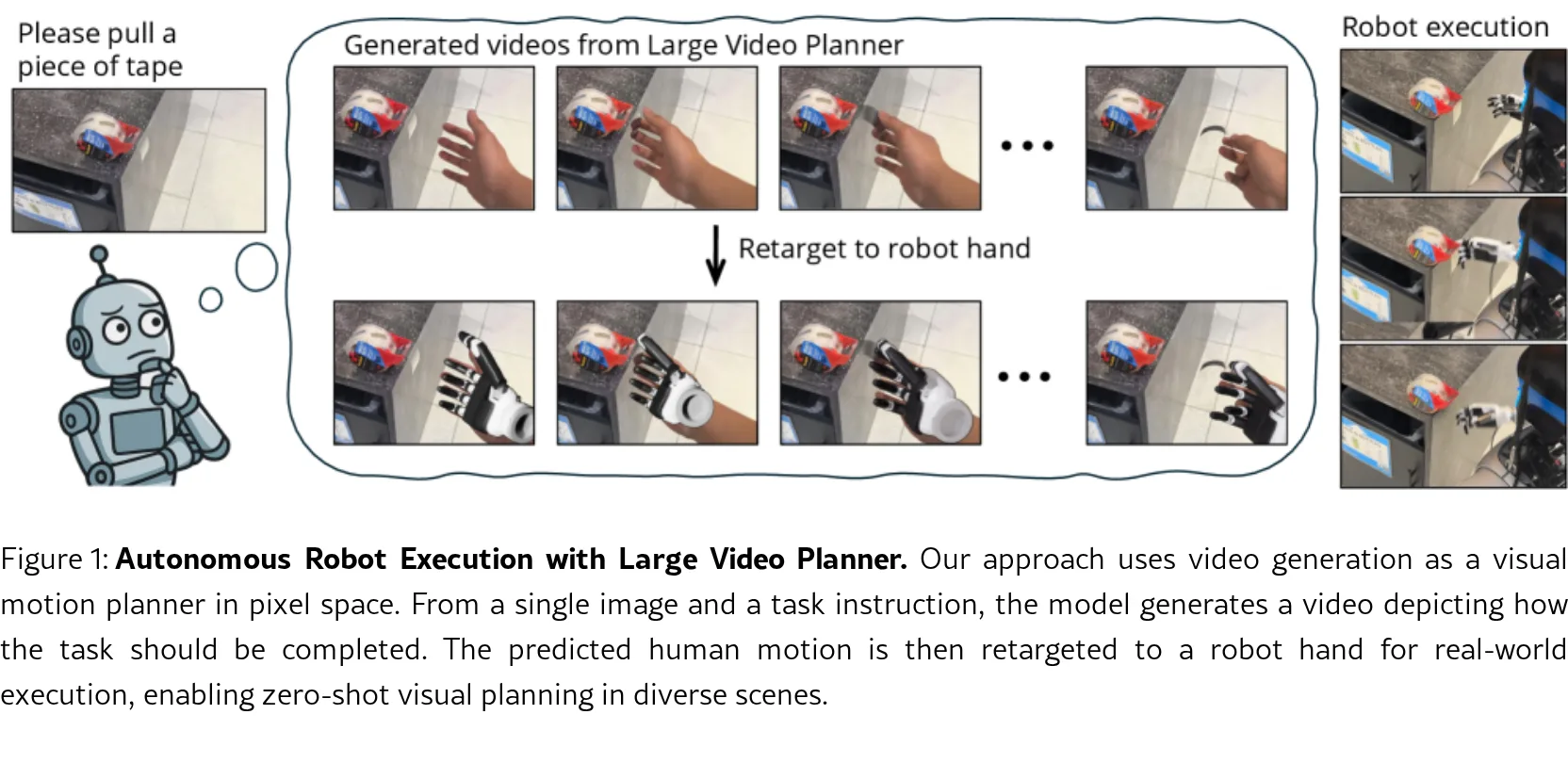
- 提出 Large Video Planner (LVP),一个140亿参数的视频基础模型,用于生成式机器人规划,实现零样本任务级泛化
- 首次在基础模型规模上训练开源视频模型用于机器人规划,生成零样本视频计划并提取可执行机器人动作
Card 01
研究单位
研究单位
- MIT(第一作者 Boyuan Chen、Tianyuan Zhang、Kiwhan Song、William T. Freeman、Russ Tedrake、Vincent Sitzmann 等)
- UC Berkeley(Haoran Geng、Caiyi Zhang、Peihao Li、Jitendra Malik、Pieter Abbeel 等)
- Harvard(Yilun Du)
Card 02
论文概述
论文概述
- 探索以视频作为主要模态构建机器人基础模型的新范式,替代传统的视觉-语言-动作(VLA)方法
- 提出 Large Video Planner (LVP),一个140亿参数的视频基础模型,用于生成式机器人规划,实现零样本任务级泛化
Card 03
核心贡献
核心贡献
- 首次在基础模型规模上训练开源视频模型用于机器人规划,生成零样本视频计划并提取可执行机器人动作
- 构建并开源 LVP-1M 数据集,包含140万条经过精心筛选的人类活动和机器人操作视频片段
- 提出结合 Diffusion Forcing 和 History Guidance 的视频生成方法,显著增强时间一致性和物理连贯性
- 通过第三方独立测试和真实机器人实验,验证任务级泛化能力,在多样化场景和任务中实现物理执行
Card 04
方法描述
方法描述
- Latent Diffusion 框架:使用时序因果3D VAE压缩视频,在隐空间训练扩散模型
- Diffusion Forcing Transformer:对不同帧应用独立噪声级别,实现灵活的图像到视频(I2V)和视频到视频(V2V)条件生成
- History Guidance:结合文本CFG和历史帧引导,增强生成视频对初始观察帧的遵循度
- 动作提取流程:通过 HaMeR 进行手部姿态估计,MegaSaM 进行4D对齐,Dex-Retargeting 重定向到机器人执行器
Card 05
数据集与资源
数据集与资源
- LVP-1M 数据集:140万条视频片段,来源包括 Bridge、DROID、AgiBot-World、Ego4D、Epic-Kitchens、Something-Something、Panda-70M 等
- 模型规模:14B 参数(基于 Wan 2.1 14B 继续预训练)
- 训练资源:128 张 H100 SXM5 GPU,约14天训练时间
- 训练数据量:200B tokens(第一阶段60k步,第二阶段10k步低相机运动微调)
Card 06
评估与结果
评估与结果
- 第三方任务评估:100个由独立测试者提出的野外任务,涵盖多样化场景(如加油站、马桶冲水、撕胶带等)
- 四级评估指标:正确接触(87.3%)、正确终止状态(63.2%)、任务完成(59.3%)、完美完成(44.0%)
- 基线对比:显著优于 Wan 2.1、Cosmos-Predict 2、Hunyuan 等视频生成模型
- 真实机器人实验:在 Franka 平行夹爪和 G1 灵巧手上测试,涵盖拾取、开门、擦桌、舀咖啡豆、撕胶带等任务,成功率显著高于 π₀ 和 OpenVLA