一眼看懂
封面预览
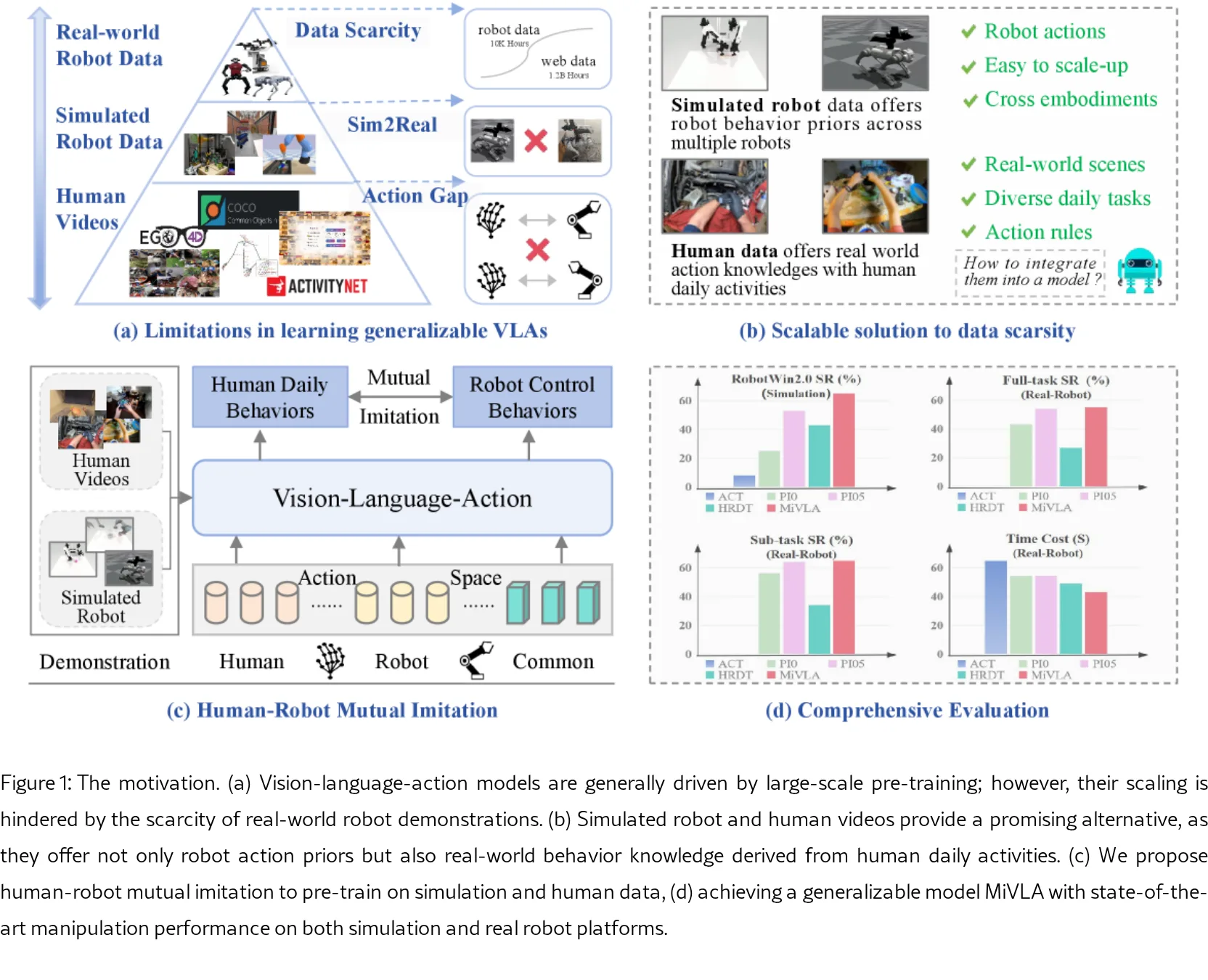
提出 MiVLA(Mutual Imitation Vision-Language-Action),一种通过人机互模仿预训练增强泛化能力的视觉…
- 提出 MiVLA(Mutual Imitation Vision-Language-Action),一种通过人机互模仿预训练增强泛化能力的视觉…
- 解决现有 VLA 模型因真实机器人数据稀缺而导致的泛化能力不足问题,利用仿真机器人数据和人类视频数据的互补先验知识
- 核心思想:通过双向动作空间对齐机制,实现人类与机器人之间的互模仿学习,无需真实机器人数据即可训练通用机器人策略
Card 01
研究单位
研究单位
- Tongji University (同济大学)
- University of Electronic Science and Technology of China (电子科技大学)
Card 02
论文概述
论文概述
- 提出 MiVLA(Mutual Imitation Vision-Language-Action),一种通过人机互模仿预训练增强泛化能力的视觉-语言-动作模型
- 解决现有 VLA 模型因真实机器人数据稀缺而导致的泛化能力不足问题,利用仿真机器人数据和人类视频数据的互补先验知识
- 核心思想:通过双向动作空间对齐机制,实现人类与机器人之间的互模仿学习,无需真实机器人数据即可训练通用机器人策略
Card 03
核心贡献
核心贡献
- 提出 MiVLA 模型,首次通过人机互模仿预训练将真实世界人类数据的行为保真度与仿真机器人数据的操作多样性统一到一个模型中
- 设计基于运动学规则的人机双向动作空间转换机制,利用左/右手坐标系对齐实现跨具身学习
- 在仿真和真实机器人平台(ARX、PiPer、LocoMan 三种机器人)上验证,相比 SOTA VLA(π₀、π₀.₅、H-RDT)提升 25%(仿真)和 14%(真实世界)
- 证明无需真实机器人数据,通过合理的预训练策略即可实现可泛化的 VLA 模型
Card 04
方法描述
方法描述
- 架构:基于多模态 tokenizer(DINOv2 + SigLIP 视觉编码,T5 语言编码)和扩散 Transformer 动作解码器
- 统一动作空间:人类关节(48维)、机器人关节(14维)、末端执行器位姿(14维)
- 人机动作映射:以拇指关节为参考点,通过旋转矩阵和逆运动学(IK)实现 Human-to-Robot 和 Robot-to-Human 双向转换
- 互模仿预训练目标:联合优化 ℓ_{h2r}(人→机器人模仿)和 ℓ_{r2h}(机器人→人模仿)两个损失函数
- 关键技术:流匹配(flow-matching)扩散过程进行连续动作生成
Card 05
数据集与资源
数据集与资源
- 仿真数据:RoboTwin-2.0 基准,50个双臂协作操作任务,2500条演示(每任务50条)
- 人类视频数据:EgoDex 等 egocentric 人类视频数据集
- 模型规模:扩散 Transformer 动作解码器
- 训练资源:预训练使用 4× A100 GPU,batch size 128;微调使用 2× A100 GPU,batch size 32;bf16 混合精度
Card 06
评估与结果
评估与结果
- 仿真评估:RoboTwin-2.0 的 20 个代表性任务(4简单+4中等+12困难),Easy/Hard 两种模式
- 真实机器人评估:3种异构机器人(PiPer 单臂、ARX-5 单臂、LocoMan 双臂),3个设计任务
- 评估指标:成功率(SR)、完成度(C)、时间开销(T)
- 关键结果:
- 仿真平均成功率:Easy 模式 69%,Hard 模式 66%,显著优于 π₀(23%/25%)、π₀.₅(35%/53%)、H-RDT(36%/43%)
- 真实世界平均成功率:55%(全任务)、69%(子任务),在复合具身 LocoMan 上表现最佳
- 小样本适应:20条演示即可适应新任务
- 跨位置/跨物体/跨场景泛化能力显著优于基线