一眼看懂
封面预览
提出一种资源高效的 VLA(Vision-Language-Action)模型微调方法,使多十亿参数的模型能在消费级 GPU(8GB VRAM…
- 提出一种资源高效的 VLA(Vision-Language-Action)模型微调方法,使多十亿参数的模型能在消费级 GPU(8GB VRAM…
- 针对低成本机器人平台(SO101 机械臂)进行真实世界部署分析,解决计算资源受限和机器人本体适应的挑战
- 研究核心问题:如何在有限演示数据下有效适配预训练 VLA 模型到新机器人本体,并分析训练数据量与部署成功率的关系
Card 01
研究单位
研究单位
- Independent Researchers, Riyadh, Saudi Arabia
- QSS AI and Robotics Lab(研究开展地点)
Card 02
论文概述
论文概述
- 提出一种资源高效的 VLA(Vision-Language-Action)模型微调方法,使多十亿参数的模型能在消费级 GPU(8GB VRAM)上运行
- 针对低成本机器人平台(SO101 机械臂)进行真实世界部署分析,解决计算资源受限和机器人本体适应的挑战
- 研究核心问题:如何在有限演示数据下有效适配预训练 VLA 模型到新机器人本体,并分析训练数据量与部署成功率的关系
Card 03
核心贡献
核心贡献
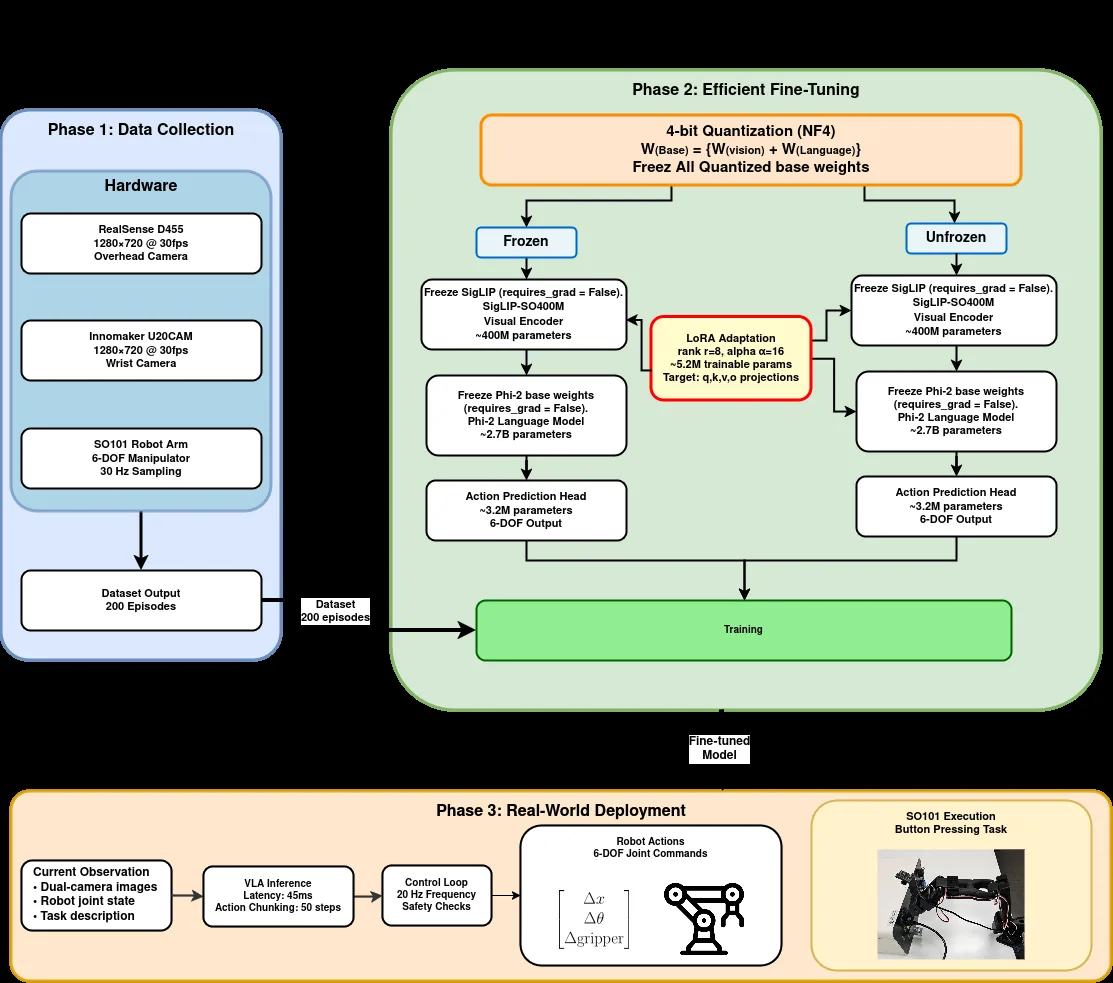
- 高效微调方法论:结合 LoRA(Low-Rank Adaptation) 和 4-bit 量化 技术,将 3.1B 参数 VLA 模型(SmolVLA)的显存需求从 24GB+ 降至 6-8GB,实现消费级 GPU 上的训练与推理
- 系统化的视觉编码器策略分析:对比冻结与解冻视觉编码器的权衡,揭示数据充足时两种策略均可达 >70% 成功率,但解冻策略视觉影响力更强(Δ_vision = 6.2 vs 4.5)
- 真实世界部署深度分析:在 SO101 机械臂上完成按钮按压任务部署,识别关键失败模式(振荡行为、弱视觉影响、目标跟踪失败),建立训练数据量与视觉影响力的定量关系
- 数据需求临界洞察:发现 200 个演示片段是实现可靠部署(74-76% 成功率)的关键阈值,不足数据会导致特征性失败模式
Card 04
方法描述
方法描述
- 基础模型:基于 SmolVLA(3.1B 参数:SigLIP-SO400M 视觉编码器 + Phi-2 语言模型 + 动作预测头)
- LoRA 配置:秩 r=8,缩放因子 α=16,应用于 32 层 Transformer 的注意力投影矩阵,可训练参数从 26.2M/层降至 163K/层(160 倍缩减)
- 量化策略:采用 BitsAndBytes NF4 量化,结合双重量化技术,实现约 8 倍显存压缩,精度损失 <2%
- 视觉编码器策略:冻结方案(8.4M 可训练参数)vs 解冻方案(33M 可训练参数,额外添加视觉 LoRA)
- 训练配置:批量大小 B=1,梯度累积 G=8,有效批量 8;AdamW 优化器,余弦退火学习率(5e-5 → 1e-6);动作分块预测(50 步)
- 部署框架:20Hz 控制频率,双摄像头( overhead RealSense D455 720p + 腕部 USB 320p),动作空间自适应与安全防护机制
Card 05
数据集与资源
数据集与资源
- 数据集:自主采集的按钮按压演示数据,LeRobot v3.0 格式,包含三种规模(20/50/200 片段,对应 5,944/14,860/59,440 帧)
- 硬件平台:SO101 六自由度机械臂(低成本开源平台,负载 0.5kg,工作空间 ~0.16m²),双摄像头视觉系统
- 计算资源:NVIDIA RTX 4060 8GB VRAM,32GB DDR4 内存,Intel i7 处理器;训练时间 10-20 GPU 小时
Card 06
评估与结果
评估与结果
- 评估任务:"按下控制器按钮开启"——包含目标定位、轨迹规划、按压执行、安全回撤的完整操作链
- 关键指标:视觉影响力(Δ_vision,有/无视觉输入的动作预测 L2 差异)、部署成功率、推理延迟、显存占用
- 核心结果:
- 200 片段训练:冻结视觉 74% 成功率,解冻视觉 76% 成功率
- 视觉影响力随数据量增长:20 片段时 0.8(弱)→ 200 片段时 4.5-6.2(强/非常强)
- 实时推理:45ms 端到端延迟,22.2 预测/秒吞吐量,峰值显存 6.8GB
- 失败模式分布(200 片段):振荡行为 40%、错误轨迹 30%、视觉跟踪失败 20%、其他 10%