一眼看懂
封面预览
提出WholeBodyVLA,首个实现双足人形机器人端到端大空间移动-操作(loco-manipulation)控制的统一框架
- 提出WholeBodyVLA,首个实现双足人形机器人端到端大空间移动-操作(loco-manipulation)控制的统一框架
- 解决人形机器人移动-操作数据稀缺问题,通过低成本无动作标注的以自我为中心的视频学习丰富的移动-操作先验知识
- 针对现有RL控制器精度不足、稳定性差的问题,提出专门面向移动-操作的离散命令接口
Card 01
研究单位
研究单位
- Fudan University(复旦大学)
- OpenDriveLab & MMLab at The University of Hong Kong(香港大学OpenDriveLab与MMLab)
- AgiBot(智元机器人)
- SII(上海人工智能实验室)
Card 02
论文概述
论文概述
- 提出WholeBodyVLA,首个实现双足人形机器人端到端大空间移动-操作(loco-manipulation)控制的统一框架
- 解决人形机器人移动-操作数据稀缺问题,通过低成本无动作标注的以自我为中心的视频学习丰富的移动-操作先验知识
- 针对现有RL控制器精度不足、稳定性差的问题,提出专门面向移动-操作的离散命令接口
Card 03
核心贡献
核心贡献
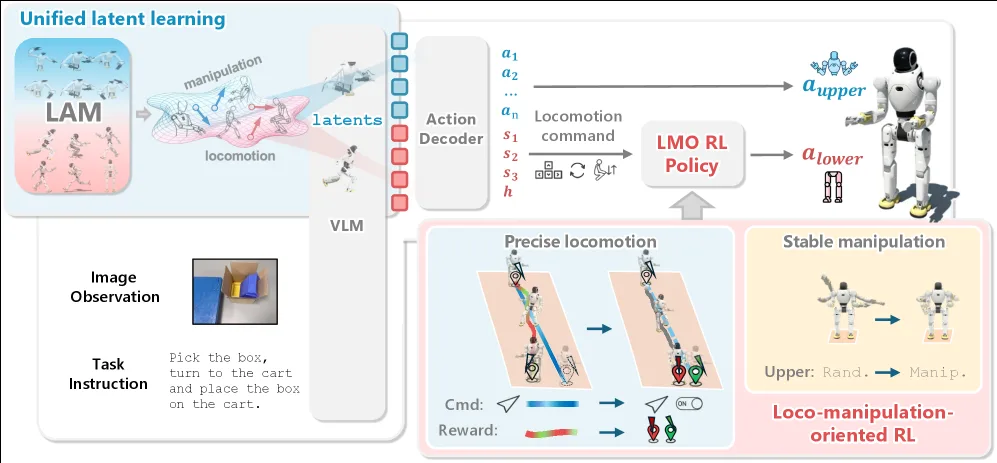
- 提出WholeBodyVLA框架,实现真实场景下自主的大空间端到端人形移动-操作
- 引入统一潜动作学习(unified latent learning),利用低成本无动作视频联合学习移动与操作,缓解遥操作数据稀缺问题
- 设计面向移动-操作的RL策略(LMO),通过离散命令接口实现精准稳定的底层控制
- 构建高效的以自我为中心的移动-操作视频数据采集流程,仅需单操作员和单目相机
- 在AgiBot X2人形机器人上验证,相比基线提升21.3%,并展现强泛化能力
Card 04
方法描述
方法描述
- 统一潜动作模型(Unified Latent Action Model):分别训练移动LAM和操作LAM,将帧间视觉变化编码为离散潜动作,作为VLA训练的监督信号;VLA同时预测两类潜动作,实现移动与操作的统一决策
- LMO RL策略:采用离散三值命令接口(前进/侧移/转向各-1/0/1)替代连续速度跟踪,配合两阶段课程学习(基础步态获取→精度稳定性优化),实现精准启停和方向控制
- 轻量级动作解码器:将潜动作解码为上肢关节角度和下肢移动命令,由LMO策略转换为高频力矩输出
Card 05
数据集与资源
数据集与资源
- AgiBot World:大规模真实机器人操作数据集,用于操作LAM预训练
- 自采集移动-操作视频:以自我为中心的低成本人形移动视频,用于移动LAM预训练
- AgiBot X2遥操作数据:每个任务50次VR+摇杆遥操作轨迹,用于微调
- 硬件平台:AgiBot X2人形机器人(7自由度手臂+Omnipicker夹爪,6自由度腿部,1自由度腰部,Intel RealSense D435i相机)
Card 06
评估与结果
评估与结果
- 评估任务:Bag Packing(抓取纸袋、侧移、蹲下放置)、Box Loading(蹲下抓取箱子、转身放置到推车)、Cart Pushing(抓握推车把手、推动50kg负载前进)
- 主要对比基线:Modular Design(模块化设计)、GR00T w/ LMO、OpenVLA-OFT w/ LMO
- 关键结果:WholeBodyVLA平均成功率78.0%,相比Modular Design(64.0%)提升21.3%,相比GR00T w/ LMO(42.0%)提升85.7%
- 消融实验:无LAM预训练成功率仅39.3%(下降38.7%);仅用操作LAM成功率63.3%;共享LAM成功率66.0%;速度基线RL控制器成功率54.0%(下降24%)
- 泛化能力:在改变起始位姿、物体、布局和外观的设置下,潜动作预训练显著减少所需遥操作数据量(50%视频预训练+25条轨迹 ≈ 25%视频预训练+200条轨迹)