一眼看懂
封面预览
论文提出 BayesVLA,一种基于贝叶斯分解的视觉-语言-动作(VLA)策略,旨在解决 VLA 模型在微调过程中的灾难性遗忘问题
- 论文提出 BayesVLA,一种基于贝叶斯分解的视觉-语言-动作(VLA)策略,旨在解决 VLA 模型在微调过程中的灾难性遗忘问题
- 核心创新在于通过"先视觉-后语言"的两阶段架构,解决 VLA 数据集中固有的模态不平衡问题(语言多样性远低于视觉-动作多样性)
- 目标是实现无需外部推理数据即可保持语言泛化能力的机器人操控策略
Card 01
研究单位
研究单位
- 浙江大学(Zhejiang University)
- 加州大学伯克利分校(UC Berkeley)
Card 02
论文概述
论文概述
- 论文提出 BayesVLA,一种基于贝叶斯分解的视觉-语言-动作(VLA)策略,旨在解决 VLA 模型在微调过程中的灾难性遗忘问题
- 核心创新在于通过"先视觉-后语言"的两阶段架构,解决 VLA 数据集中固有的模态不平衡问题(语言多样性远低于视觉-动作多样性)
- 目标是实现无需外部推理数据即可保持语言泛化能力的机器人操控策略
Card 03
核心贡献
核心贡献
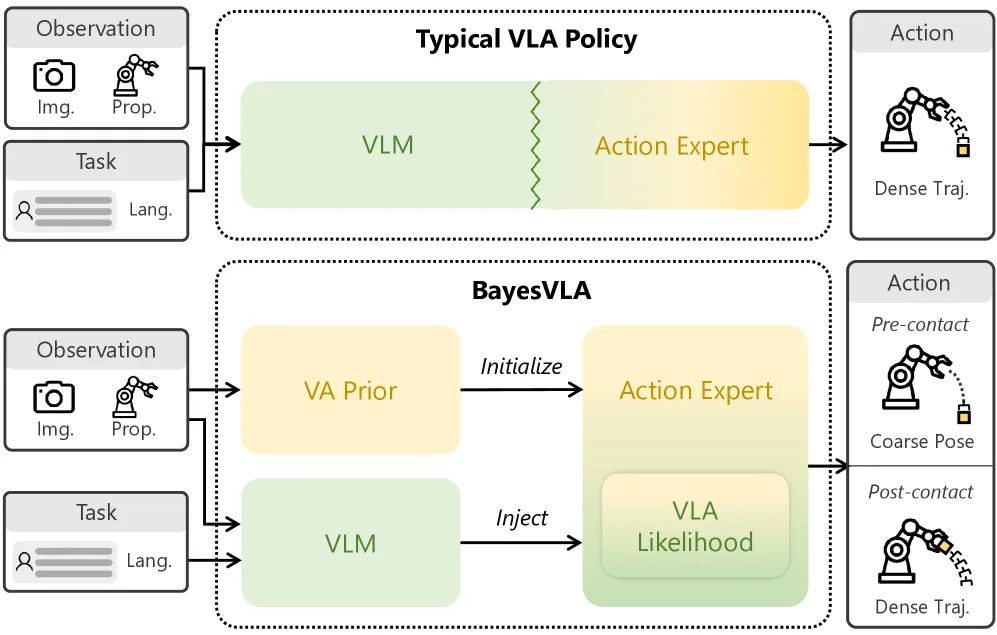
- 贝叶斯分解框架:将 VLA 策略分解为视觉-动作先验(seeing to act)和语言条件似然(prompting to specify),从结构上处理模态不平衡
- 分阶段架构设计:针对接触前(pre-contact)和接触后(post-contact)阶段分别设计专门的策略架构
- 信息理论验证:通过信息论分析形式化证明该方法能有效缓解捷径学习(shortcut learning)
- 轻量化语言适应:仅需微调少量参数即可实现语言对齐,保留预训练模型的泛化能力
- 全面实验验证:在模拟和真实环境中均展现出优越的泛化性能
Card 04
方法描述
方法描述
- 两阶段训练流程:第一阶段训练视觉-动作先验模型,第二阶段训练语言条件似然模型进行对齐
- 接触前阶段:利用预训练的抓取基础模型(如 AnyGrasp)作为先验,通过交叉注意力机制实现文本感知的动作选择
- 接触后阶段:采用扩散模型生成多模态轨迹,通过"后期注入"(late-injection)注意力层引入语言条件
- 训练策略:提出两种训练配方(R1/R2),根据数据规模和语言多样性灵活选择
- 动作表示:使用 SE(3) 流形上的相对末端执行器位姿表示,实现跨本体泛化
Card 05
数据集与资源
数据集与资源
- 预训练数据:DROID 数据集(78,544 条轨迹)
- 模拟基准:LIBERO、LIBERO-PRO、刚性物体拾取放置、铰接物体操作
- 真实世界实验:拾取放置任务、冰箱存储任务、杂乱环境拾取放置
- 视觉编码器:CLIP ViT-L/14
- 优化器:AdamW,学习率 1e-4,批量大小 32
- 训练迭代:先验模型 400k 次,似然模型 200k 次
Card 06
评估与结果
评估与结果
- LIBERO-PRO 泛化测试:在位置扰动(Pos)上达到 21%(对比 π₀ 的 0%),在任务指令变化(Task)上达到 10%(对比 π₀.₅ 的 1%),在环境变化(Env)上达到 81%
- 刚性物体拾取放置:在未见物体(UO)和未见容器(UC)设置下显著优于基线方法
- 消融研究:验证了贝叶斯分解、两阶段训练和预训练策略的有效性
- 真实世界验证:在多种任务中展现出对新物体、新指令和新环境的强泛化能力