一眼看懂
封面预览
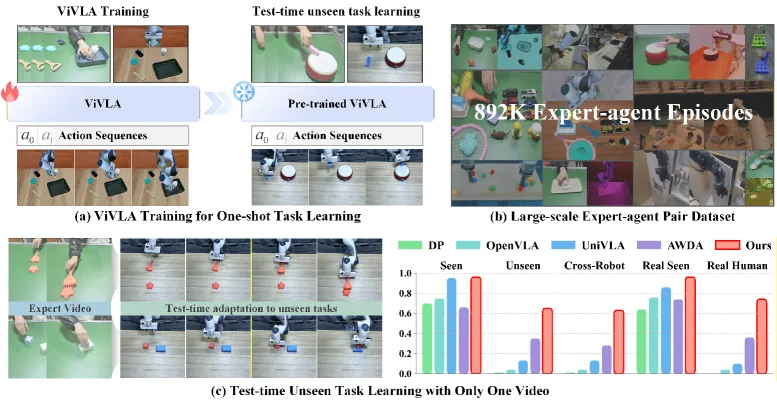
提出了 ViVLA(Vision-Language-Action)模型,使机器人能够在测试时通过观看一次专家演示视频来学习新任务,实现 一次示…
- 提出了 ViVLA(Vision-Language-Action)模型,使机器人能够在测试时通过观看一次专家演示视频来学习新任务,实现 一次示…
- 要解决的核心问题是现有视觉-语言-动作模型在训练分布之外的任务上泛化能力有限,无法像人类一样通过观察快速掌握新技能。
- 提出了一种新颖的 VLA 范式,能够从专家视频中提炼细粒度的操作知识并无缝传递给机器人,无需额外的训练或微调。
Card 01
研究单位
研究单位
- 北京理工大学
- LimX Dynamics
Card 02
论文概述
论文概述
- 提出了 ViVLA(Vision-Language-Action)模型,使机器人能够在测试时通过观看一次专家演示视频来学习新任务,实现 一次示范视频任务学习。
- 要解决的核心问题是现有视觉-语言-动作模型在训练分布之外的任务上泛化能力有限,无法像人类一样通过观察快速掌握新技能。
Card 03
核心贡献
核心贡献
- 提出了一种新颖的 VLA 范式,能够从专家视频中提炼细粒度的操作知识并无缝传递给机器人,无需额外的训练或微调。
- 引入了包含循环一致性约束的潜在动作学习框架,构建了一个统一潜在动作空间。并采用并行解码机制来缓解捷径学习问题,提升推理效率。
- 提出了一个可扩展的专家-智能体配对数据生成管道,利用人类视频合成轨迹对,并结合公开数据集,构建了包含 892,911 个配对样本的大规模数据集。
- 实验证明,所提方法在 LIBERO 基准测试的未见任务上实现了超过 30% 的性能提升,利用跨实体视频和人机视频学习也带来了显著的性能增益。
Card 04
方法描述
方法描述
- 方法分为两个阶段:1)基于动作中心循环一致性的潜在动作学习:训练一个编码器-解码器架构的潜在动作标记器(Latent Action Tokenizer),并使用动作中心的循环一致性(Action-Centric Cycle Consistency)来对齐和统一专家视频与机器人轨迹的潜在动作表示空间。2)ViVLA 训练与一次性任务学习:在 Qwen2.5-VL 模型基础上进行微调,采用时空掩码策略(Temporal-Spatial Masking)减少视频冗余并增强理解能力,采用并行解码策略预测动作序列。模型输入包括掩码后的专家视频、机器人当前观测和语言指令,同时预测专家视频中的动作序列和机器人后续动作。
- 创新点包括:动作中心循环一致性约束以统一动作表示;并行解码以避免自回归训练中的捷径学习并加速推理;时空掩码与细粒度动作推理目标以增强模型理解。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括自建的 Human2Robot(89,736 对样本)以及来自 Fractal、Bridge、Droid、Language Table、BC-Z、FMB、Ego4D、EgoDex 等公开数据集经过配对处理后的数据,总计 892,911 个专家-智能体配对样本。
- 模型基于 Qwen2.5-VL(720亿参数)进行构建和微调。
- 训练使用 GPU 进行,全局批处理大小为 256。
Card 06
评估与结果
评估与结果
- 评估环境与基准:主要在 LIBERO 机器人模拟基准上进行评估,包含空间泛化、物体泛化、目标泛化和长时任务四个子集。评估时,测试集任务在训练中完全未见。
- 主要评估指标:任务成功率。
- 关键实验结果:在 LIBERO 所有未见任务上达到 65% 的成功率,相比 Diffusion Policy (1%)、OpenVLA (4%)、UniVLA (13%) 和 AWDA (35%) 等基线方法有显著提升(超过 30%)。在利用不同机器人本体(跨实体)视频进行学习时,成功率仍高达 63%。在真实世界利用人类视频学习未见任务时,也获得了 超过38% 的绝对性能提升。