一眼看懂
封面预览
论文提出Affordance Field Intervention (AFI),一个轻量级的混合框架,用于解决视觉-语言-动作模型在机器人操作…
- 论文提出Affordance Field Intervention (AFI),一个轻量级的混合框架,用于解决视觉-语言-动作模型在机器人操作…
- 核心目标是增强VLA模型在分布外场景下的鲁棒性,使其能够摆脱对训练轨迹的刚性记忆,并适应环境变化(如物体位置移动)。
- 论文通过将3D空间可供性场作为即插即用模块来引导VLA的动作生成,实现无需参数更新的在线干预。
Card 01
研究单位
研究单位
- 悉尼大学 计算机学院 (The University of Sydney, School of Computer Science)
- 上海交通大学 约翰·霍普克罗夫特计算机科学中心 (John Hopcropt Center for Computer Science, Shanghai Jiao Tong University)
Card 02
论文概述
论文概述
- 论文提出Affordance Field Intervention (AFI),一个轻量级的混合框架,用于解决视觉-语言-动作模型在机器人操作中面临的“记忆陷阱”问题。
- 核心目标是增强VLA模型在分布外场景下的鲁棒性,使其能够摆脱对训练轨迹的刚性记忆,并适应环境变化(如物体位置移动)。
- 论文通过将3D空间可供性场作为即插即用模块来引导VLA的动作生成,实现无需参数更新的在线干预。
Card 03
核心贡献
核心贡献
- 提出了Affordance Field Intervention (AFI) 框架,首次将3D空间可供性场作为VLA模型的即插即用干预模块。
- 设计了一种基于本体感知的记忆陷阱检测机制,通过监测末端执行器运动模式和目标距离来识别失败。
- 提出了分层轨迹探索策略,通过历史回滚和SAF引导的路径点采样,引导VLA逃离陷阱并生成最优动作轨迹。
- 该框架是模型无关的,无需重新训练VLA模型或额外数据,可无缝集成到不同VLA主干网络中。
- 在真实世界和仿真环境中进行了广泛验证,显著提升了VLA模型在多种分布偏移场景下的成功率。
Card 04
方法描述
方法描述
- 方法核心是一个混合框架,将空间可供性场作为VLA动作生成的“干预器”。
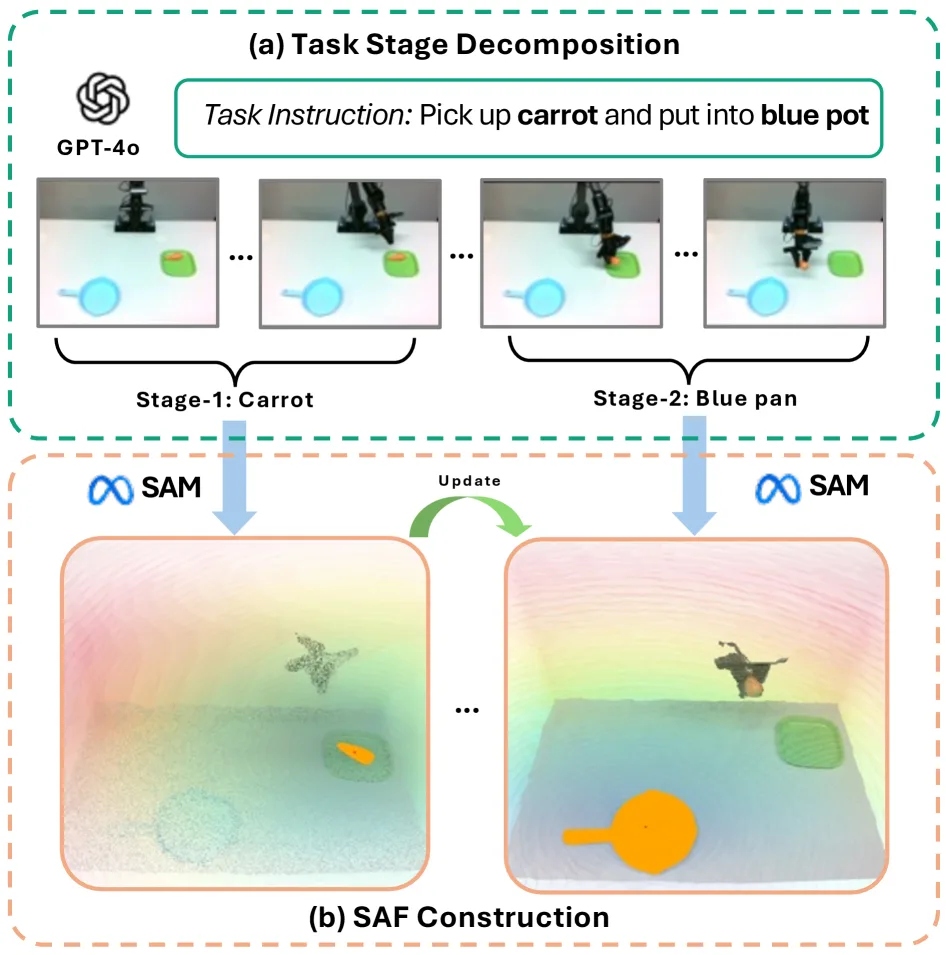
- 关键技术:1) 使用GPT-4o分解任务指令并识别目标物体,结合Grounded-SAM进行分割,将2D掩码反投影到3D空间构建SAF;2) SAF由目标引导场(吸引至目标)和障碍物规避场融合而成;3) 记忆陷阱检测基于末端执行器位移停滞且远离目标;4) 干预过程包括:回滚到历史高可供性位置、在局部采样SAF引导的路径点、在路径点处用VLA生成多个候选动作、最后通过SAF成本打分选择最优轨迹执行。
Card 05
数据集与资源
数据集与资源
- 真实世界任务:在AgileX Piper机械臂上评估了四个任务(放置胡萝卜、移除盖子、插笔、堆叠胶带)。
- 仿真基准:使用了LIBERO-Pro基准(LIBERO-Spatial 和 LIBERO-Object 套件),并引入空间扰动。
- 模型规模:使用了两个预训练的VLA主干模型 π₀ 和 π₀.₅。
- 训练/推理资源:模型微调使用单个NVIDIA H100 GPU。SAF构建与推理在NVIDIA RTX 4090和NVIDIA GeForce GTX 1080Ti GPU上进行。真实机器人平台配备Intel RealSense D435摄像头。
Card 06
评估与结果
评估与结果
- 评估环境:真实世界机器人平台(AgileX Piper)和仿真环境(LIBERO)。
- 评估指标:任务成功率,在多种分布外场景下评估,包括位置偏移、颜色变化、物体属性和背景变化。
- 关键结果:
- 在真实世界任务中,AFI相对于基线VLA(π₀ 和 π₀.₅)平均提升23.5%的成功率。
- 在LIBERO-Pro仿真基准上,AFI将π₀.₅的成功率提升了21.7%(Spatial)和16.8%(Object)。
- 框架具有模型无关性,集成多个VLA主干(π₀ + π₀.₅)时,在堆叠胶带任务中取得了89.0%的最高成功率。
- 消融实验证实了历史回滚机制和自适应检测的关键作用,以及10个路径点的采样数量能达到最佳效果。