一眼看懂
封面预览
论文研究了视觉-语言-动作模型在推理阶段的脆弱性问题,即模型在经监督微调后,不同采样噪声会导致任务成功率出现剧烈波动。
- 论文研究了视觉-语言-动作模型在推理阶段的脆弱性问题,即模型在经监督微调后,不同采样噪声会导致任务成功率出现剧烈波动。
- 将此不稳定性归因于VLA策略分布与下游任务成功模式诱导的策略分布之间存在偏移,导致模型生成非预期或次优的动作。
- 提出了TACO框架,通过测试时缩放与反探索原则,约束生成动作位于成功行为数据支持集内,以提升推理稳定性与任务成功率。
Card 01
研究单位
研究单位
- 中国电信人工智能研究院
- 中国科学技术大学
- 清华大学
- 香港科技大学
Card 02
论文概述
论文概述
- 论文研究了视觉-语言-动作模型在推理阶段的脆弱性问题,即模型在经监督微调后,不同采样噪声会导致任务成功率出现剧烈波动。
- 将此不稳定性归因于VLA策略分布与下游任务成功模式诱导的策略分布之间存在偏移,导致模型生成非预期或次优的动作。
- 提出了TACO框架,通过测试时缩放与反探索原则,约束生成动作位于成功行为数据支持集内,以提升推理稳定性与任务成功率。
Card 03
核心贡献
核心贡献
- 提出了TACO,一个测试时缩放框架,在将VLA输出约束至特定下游任务成功模式的同时,有效保留预训练模型的强泛化能力。
- 为VLA模型引入了一种高效的内部表示机制用于伪计数估计,能够以极小的计算开销精确衡量分布偏移。
- 实验证明TACO能显著提升多种VLA模型在仿真与真实世界任务中的成功率,且无需延长训练时间,并具备低延迟运行能力。
Card 04
方法描述
方法描述
- 将推理不稳定性建模为分布外问题,借鉴离线强化学习中的反探索原则,旨在将生成动作约束在成功行为数据的支持集内。
- 使用硬币翻转网络作为轻量级验证器,对观测-指令-动作块进行伪计数估计,高伪计数的动作块意味着更符合成功行为数据分布。
- 提出高保真特征搜索流程,从VLA模型的内部表示中提取最具代表性的特征用于训练CFN,解决了生成式VLA只见过带噪动作的挑战。
- 在推理阶段采用生成-验证机制:并行生成多个候选动作,利用CFN评分并选择伪计数最高的动作执行,并通过KV缓存复用视觉-语言表示以降低延迟。
Card 05
数据集与资源
数据集与资源
- 仿真基准:RoboTwin2.0, RoboTwin1.0, LIBERO, SimplerEnv。
- 基础模型:π₀, π₀.₅, RDT-1B, OpenVLA。
- 真实世界平台:双臂机器人操作平台。
- 训练资源:论文未明确说明具体硬件(如GPU/TPU)细节。
Card 06
评估与结果
评估与结果
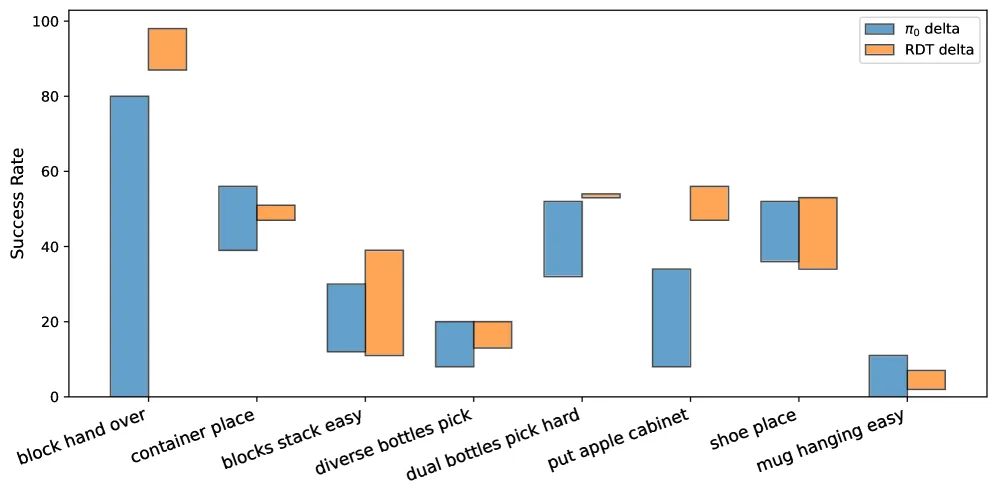
- 评估环境:四个仿真基准(共64个任务)及真实世界双臂平台上的5个任务。
- 主要评估指标:任务成功率。
- 关键实验结果:
- 在RoboTwin 1.0上,TACO使基座模型π₀的平均成功率从32.2%提升至41.3%。
- 在Simpler-WindowX上,平均成功率从48.0%提升至55.5%,提升幅度达7.5%。
- 在RoboTwin2.0上,TACO使π₀.₅的平均成功率从59.3%提升至64.0%。
- 在LIBERO上,即使基座模型π₀.₅已达94.8%的高成功率,TACO仍将其进一步提升至96.6%。
- 在真实机器人任务上,TACO在多数任务上显著提升了成功率。