一眼看懂
封面预览
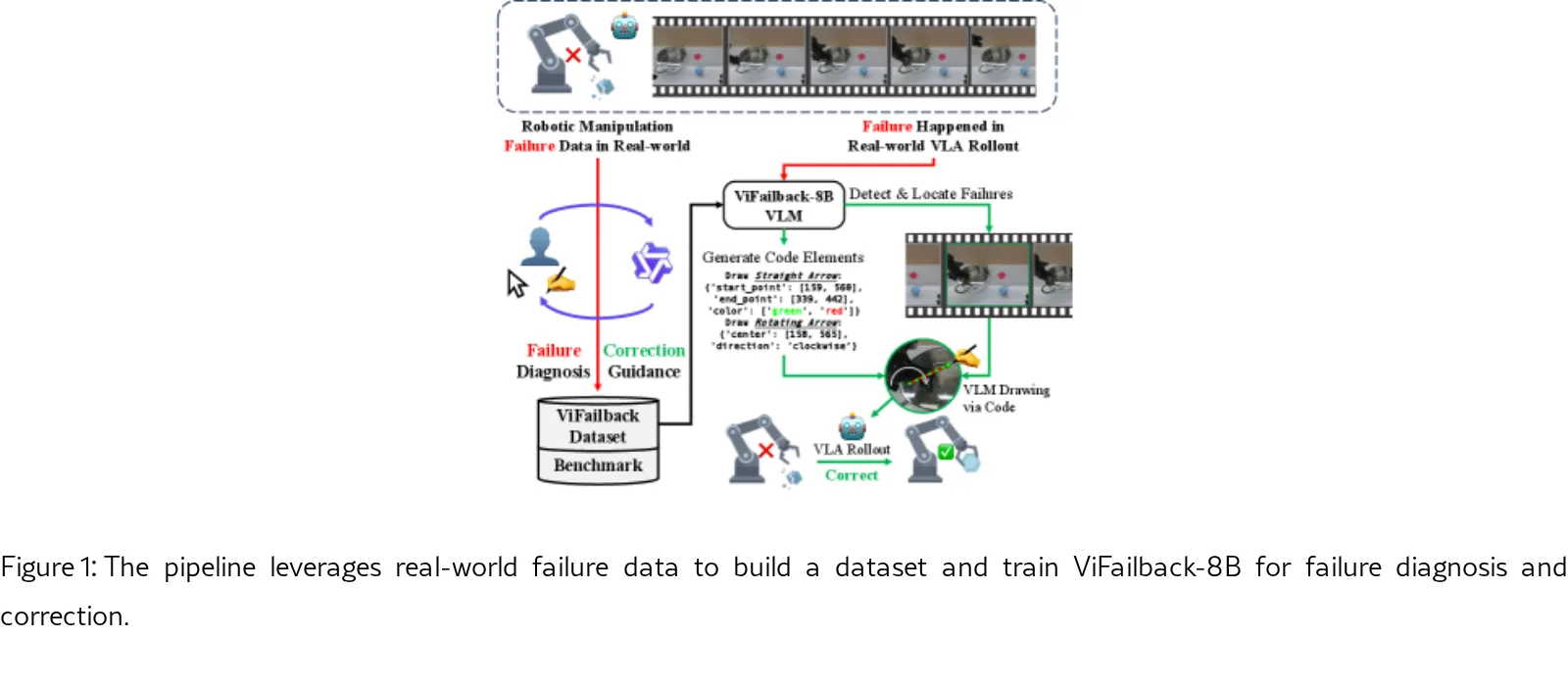
论文提出了 ViFailback 框架,旨在通过视觉符号诊断机器人操作失败并提供文本和视觉纠正指导。
- 论文提出了 ViFailback 框架,旨在通过视觉符号诊断机器人操作失败并提供文本和视觉纠正指导。
- 解决了现有 VLA 模型在面对分布外(OOD)条件时缺乏失败诊断与恢复能力的问题,以及现有失败数据集多基于模拟而难以泛化到真实世界的局限性。
- 构建了大规模真实世界数据集 ViFailback 和基准 ViFailback-Bench,并训练了专用模型以验证框架的有效性。
Card 01
研究单位
研究单位
- 北京航空航天大学
- 上海创新研究所
- 南方科技大学
- 上海交通大学
Card 02
论文概述
论文概述
- 论文提出了 ViFailback 框架,旨在通过视觉符号诊断机器人操作失败并提供文本和视觉纠正指导。
- 解决了现有 VLA 模型在面对分布外(OOD)条件时缺乏失败诊断与恢复能力的问题,以及现有失败数据集多基于模拟而难以泛化到真实世界的局限性。
- 构建了大规模真实世界数据集 ViFailback 和基准 ViFailback-Bench,并训练了专用模型以验证框架的有效性。
Card 03
核心贡献
核心贡献
- 提出了 ViFailback 框架,利用显式视觉符号高效标注真实世界的机器人失败视频。
- 发布了包含 58,126 个 VQA 对的大规模数据集,涵盖 5,202 条真实世界操作轨迹,并建立了包含 11 个细粒度任务的 ViFailback-Bench 基准。
- 基于数据集微调得到了 ViFailback-8B 模型,该模型在基准测试中表现优异,并在真实机器人实验中成功辅助 VLA 模型从失败中恢复。
Card 04
方法描述
方法描述
- 设计了 7 种视觉符号用于标注,分为 运动符号(如彩色直箭头、半圆箭头)、空间关系符号(如十字准线)和 状态符号(如 ON/OFF 标签、禁止图标)。
- 定义了细粒度任务,包括失败诊断(检测、定位、类型识别、原因分析)和纠正行动指导(低级文本、高级文本、视觉指导)。
- 采用多阶段数据标注流水线,结合人工操作与 VLM(如 Qwen3-VL-235B)辅助生成高质量标注。
- 基于 Qwen3-VL-8B 模型进行微调,使其能够生成视觉符号和纠正指导。
Card 05
数据集与资源
数据集与资源
- ViFailback 数据集:包含 58,126 个 VQA 对,源自 5,202 条真实世界轨迹,覆盖 100 个不同任务。
- ViFailback-Bench 基准:包含 500 条轨迹,分为 Lite(封闭式 VQA)和 Hard(开放式 VQA)两个版本。
- 训练资源:使用 4 张 NVIDIA Hopper GPUs,采用 LoRA 微调技术。
Card 06
评估与结果
评估与结果
- 评估环境:在 ViFailback-Bench 上对比了 16 个 SOTA 模型(包括 GPT-4o、Gemini-2.5-Pro 等)。
- 评估指标:封闭式问题使用准确率,开放式问题使用基于 GPT-4o 的评分(语义相似度、内容完整性、功能等效性)。
- 关键结果:ViFailback-8B 在基准测试中显著优于其他开源和闭源模型;在真实世界机器人实验中,集成该模型使任务平均成功率提升了 22.2%。