一眼看懂
封面预览
提出了一个名为 RoboWheel 的数据引擎,旨在将现实世界的人类手-物体交互(HOI)视频转换为可用于跨形态机器人学习的训练数据。
- 提出了一个名为 RoboWheel 的数据引擎,旨在将现实世界的人类手-物体交互(HOI)视频转换为可用于跨形态机器人学习的训练数据。
- 该引擎构建了一个端到端的流水线,涵盖视频重建、物理优化、跨具体化重定向及仿真数据增强,以解决机器人演示数据收集成本高、多样性不足的问题。
- 基于此引擎,构建了大规模多模态数据集 HORA,以支持机器人学习和HOI相关任务。
Card 01
研究单位
研究单位
- Tsinghua University
- Synapath
- The Chinese University of Hong Kong (CUHK)
- The University of Hong Kong (HKU)
- The Hong Kong Polytechnic University (PolyU)
Card 02
论文概述
论文概述
- 提出了一个名为 RoboWheel 的数据引擎,旨在将现实世界的人类手-物体交互(HOI)视频转换为可用于跨形态机器人学习的训练数据。
- 该引擎构建了一个端到端的流水线,涵盖视频重建、物理优化、跨具体化重定向及仿真数据增强,以解决机器人演示数据收集成本高、多样性不足的问题。
- 基于此引擎,构建了大规模多模态数据集 HORA,以支持机器人学习和HOI相关任务。
Card 03
核心贡献
核心贡献
- 提出了一个从单目RGB(D)输入进行物理合理的HOI重建框架,并支持跨具体化(机械臂、灵巧手、人形机器人)的动作重定向。
- 构建了一个基于仿真的数据增强框架,通过多样化的域随机化(如具体化、轨迹、物体替换、背景纹理)来扩展数据规模和多样性。
- 发布了一个包含超过15万条轨迹的大规模多模态数据集 HORA,整合了多视角捕捉、单目视频和公开HOI数据,部分数据包含触觉信号。
Card 04
方法描述
方法描述
- 技术方法包含四个阶段:首先从视频进行HOI重建,利用SDF惩罚和强化学习优化器来避免穿透并确保物理合理性与机器人可达性。
- 然后将优化后的轨迹重定向到异构机器人形态,生成可执行的动作序列。
- 接着在仿真环境中进行大规模数据增强,丰富观察和动作的多样性。
- 创新点在于将HOI重建、物理优化与跨具体化重定向和仿真增强紧密结合,形成完整的数据生产流水线。
Card 05
数据集与资源
数据集与资源
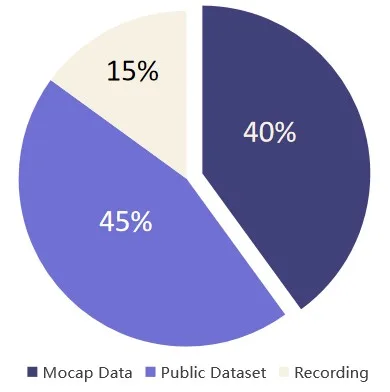
- 数据集:HORA 数据集,由 Mocap Subset、Recording Subset 和 Public HOI Subset 三部分组成,总计超过 150,000 条轨迹。
- 模型规模:论文主要关注数据引擎和数据集构建,未提及特定模型参数量。
- 训练资源:实验在 Isaac Sim 仿真环境中进行,使用了 cuRobo 的GPU加速逆运动学后端。
Card 06
评估与结果
评估与结果
- 评估环境:在HOI重建质量、下游VLA/IL策略性能及真实机器人重放三个层面进行验证。
- 主要评估指标:HOI重建质量使用CD、F-score、手部抖动和MPJPE等指标;策略性能使用任务成功率。
- 关键实验结果:RoboWheel 的HOI重建质量(如CD 5.1 cm, F10 89.1%)显著优于基线方法;使用 HORA 数据训练的策略(如RDT+5k HORA)在真实任务中取得了与遥操作数据相当甚至更好的性能,验证了数据的有效性。