一眼看懂
封面预览
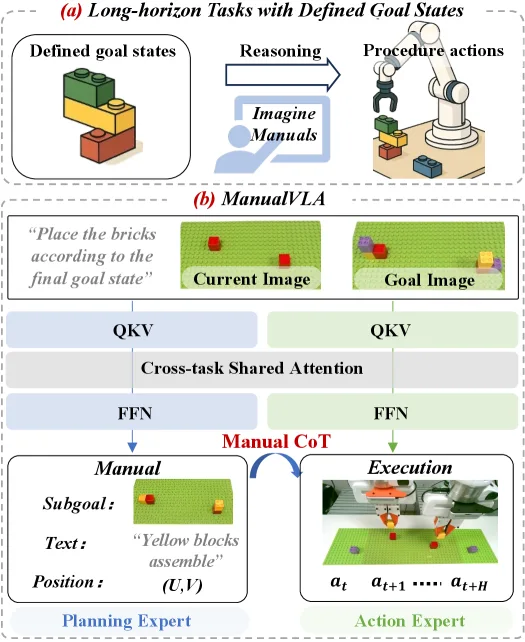
论文提出了 ManualVLA,这是一个基于混合Transformer架构的统一视觉-语言-动作(VLA)模型,旨在解决具有明确目标状态的长期…
- 论文提出了 ManualVLA,这是一个基于混合Transformer架构的统一视觉-语言-动作(VLA)模型,旨在解决具有明确目标状态的长期…
- 该模型的核心目标是从最终的“目标状态”推断出程序性的“操作手册”,并将高层规划与精确操作相结合。
- 解决了现有VLA模型在面对如乐高拼装或物体重新排列等需要长期规划和精确控制的任务时表现不佳的问题。
Card 01
研究单位
研究单位
- 北京大学(多媒体信息处理国家重点实验室、计算机学院)
- 香港中文大学
- Simplexity Robotics
Card 02
论文概述
论文概述
- 论文提出了 ManualVLA,这是一个基于混合Transformer架构的统一视觉-语言-动作(VLA)模型,旨在解决具有明确目标状态的长期机器人操作任务。
- 该模型的核心目标是从最终的“目标状态”推断出程序性的“操作手册”,并将高层规划与精确操作相结合。
- 解决了现有VLA模型在面对如乐高拼装或物体重新排列等需要长期规划和精确控制的任务时表现不佳的问题。
Card 03
核心贡献
核心贡献
- 提出了 ManualVLA 框架,这是首个尝试通过统一VLA模型解决长期、目标条件下的操作任务的方法,支持多模态手册生成与动作执行的协作。
- 设计了 Manual Chain-of-Thought (ManualCoT) 推理过程,将生成的手册转化为精确动作,其中包含显式的控制条件和隐式的潜在引导。
- 开发了基于 3D Gaussian Splatting 的高保真数字孪生工具包,用于自动生成规划专家的训练数据,减轻了数据收集负担。
- 在长期任务中实现了比现有分层SOTA基线平均高出 32% 的成功率。
Card 04
方法描述
方法描述
- 模型架构基于 Janus-Pro 和 DeepSeek-LLM 1.5B,通过 Mixture-of-Transformers (MoT) 扩展了标准Transformer,引入了规划专家和动作专家。
- 规划专家负责生成包含文本描述、目标坐标和子目标图像的多模态中间手册。
- 提出了 ManualCoT 推理策略:显式CoT通过将预测坐标作为掩码叠加在当前图像上形成视觉提示;隐式CoT通过跨任务共享注意力机制利用潜在表示引导动作生成。
- 采用三阶段训练策略:动作专家预训练、手册专家预训练、以及联合微调。
Card 05
数据集与资源
数据集与资源
- 预训练数据:整理了包含超过 40万条 轨迹的大规模跨具身数据集(来自 Open X-Embodiment, Droid, Robomind)。
- 手册生成数据:使用数字孪生工具包自动生成,每个任务包含超过 1万帧 数据。
- 微调数据:通过主从遥操作为每个下游任务收集了 100条 演示数据。
- 计算资源:使用 8张 NVIDIA H20 GPU 进行训练。
Card 06
评估与结果
评估与结果
- 评估环境:真实世界的双臂 Franka Research 3 机器人平台以及 RLBench 仿真基准。
- 主要任务:2D/3D 乐高拼装、物体重新排列。
- 关键结果:
- 在真实世界长期任务中,ManualVLA 的最终任务完成率比最强分层基线提高了 15%-30%。
- 在 RLBench 仿真实验中,平均成功率达到 70%,优于 $\pi_0$ 和 CoT-VLA 等现有SOTA方法。
- 消融实验证明了显式CoT、隐式CoT以及MoT架构对性能提升的关键作用。