一眼看懂
封面预览
论文旨在解决 Vision-Language-Action (VLA) 模型 在分布偏移下性能下降以及在复杂多步任务中表现不佳的问题。
- 论文旨在解决 Vision-Language-Action (VLA) 模型 在分布偏移下性能下降以及在复杂多步任务中表现不佳的问题。
- 核心观点是观测特征与动作嵌入之间的分布差异可作为有意义的几何信号,低运输成本表示表示兼容,高成本则暗示潜在对齐错误。
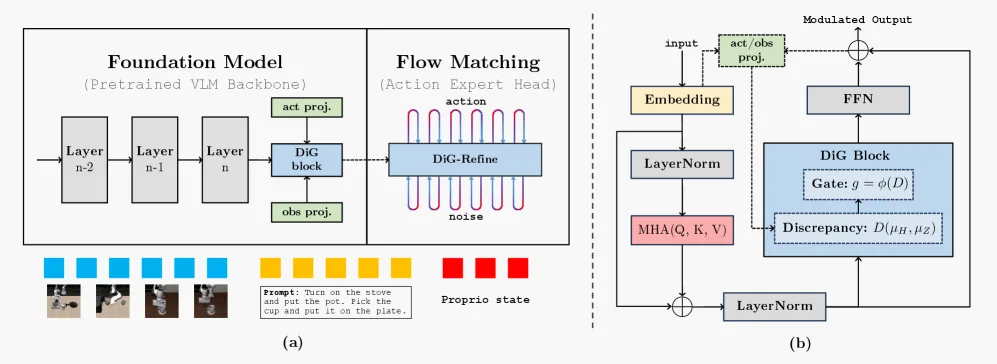
- 提出了 DiG-Flow 框架,通过几何正则化增强 VLA 模型的鲁棒性。
Card 01
研究单位
研究单位
- Peking University
- BeingBeyond
- Renmin University of China
Card 02
论文概述
论文概述
- 论文旨在解决 Vision-Language-Action (VLA) 模型 在分布偏移下性能下降以及在复杂多步任务中表现不佳的问题。
- 核心观点是观测特征与动作嵌入之间的分布差异可作为有意义的几何信号,低运输成本表示表示兼容,高成本则暗示潜在对齐错误。
- 提出了 DiG-Flow 框架,通过几何正则化增强 VLA 模型的鲁棒性。
Card 03
核心贡献
核心贡献
- 建立了一个用于鲁棒 VLA 学习的差异引导框架。
- 为该通用问题提供了理论动机,并为其方法设计提供了理论保证。
- 通过仿真和真实世界基准验证,证明了 DiG-Flow 能持续提升性能,尤其在复杂多步任务和数据有限场景下增益显著,且计算开销可忽略。
Card 04
方法描述
方法描述
- 方法包含三个主要组件:差异函数(量化分布距离)、权重映射(将差异转换为调制因子)和残差算子(调整观测特征)。
- 默认使用 Wasserstein 距离作为差异度量,因其具有几何可解释性。
- 关键创新在于,DiG-Flow 在流匹配之前的表示层面进行干预,保持了概率路径和目标向量场不变。
Card 05
数据集与资源
数据集与资源
- 使用了 LIBERO Benchmark 和 RoboCasa Benchmark 进行仿真实验。
- 进行了真实机器人实验。
- 方法计算开销可忽略。
Card 06
评估与结果
评估与结果
- 评估环境包括仿真基准和真实机器人设置,并进行了鲁棒性分析(如背景变化、人为干扰)。
- 主要评估指标是任务成功率。
- 关键结果表明,DiG-Flow 在复杂多步任务和数据有限场景下性能提升尤为明显。