一眼看懂
封面预览
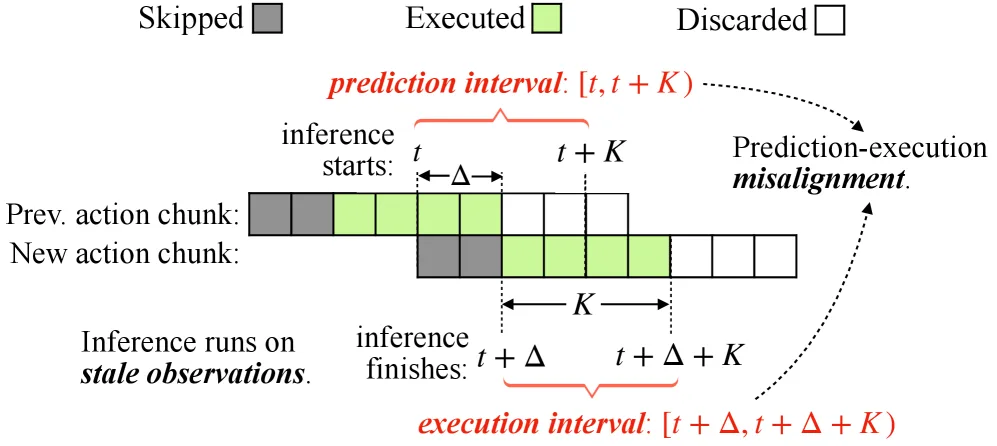
论文针对视觉-语言-动作模型在实时部署中存在的动作停顿和反应延迟问题,提出了一种通用的异步推理框架 VLASH。
- 论文针对视觉-语言-动作模型在实时部署中存在的动作停顿和反应延迟问题,提出了一种通用的异步推理框架 VLASH。
- 该方法通过“未来状态感知”技术,解决了异步推理中预测区间与执行区间的时间错位问题,实现了平滑、精确且快速反应的机器人控制。
- 论文旨在消除同步推理导致的动作停滞,同时避免朴素异步推理带来的控制不稳定和精度下降。
Card 01
研究单位
研究单位
- MIT
- NVIDIA
- Tsinghua University
- UC Berkeley
- UCSD
- Caltech
Card 02
论文概述
论文概述
- 论文针对视觉-语言-动作模型在实时部署中存在的动作停顿和反应延迟问题,提出了一种通用的异步推理框架 VLASH。
- 该方法通过“未来状态感知”技术,解决了异步推理中预测区间与执行区间的时间错位问题,实现了平滑、精确且快速反应的机器人控制。
- 论文旨在消除同步推理导致的动作停滞,同时避免朴素异步推理带来的控制不稳定和精度下降。
Card 03
核心贡献
核心贡献
- 提出了 未来状态感知 机制,通过利用先前生成的动作块前向推演机器人状态,有效弥合了预测与执行之间的时间差。
- 设计了基于时间偏移和共享观测注意力机制的高效微调策略,无需额外的推理开销即可让模型学会利用未来状态信息。
- 引入了 动作量化 技术,通过将细粒度的微动作聚合为粗粒度的宏动作,进一步加速机器人的物理运动。
- 成功展示了 VLASH 使 VLA 模型能够执行如 乒乓球对打 等高动态交互任务,这在同步推理下是无法实现的。
Card 04
方法描述
方法描述
- 未来状态估计:在推理开始时,利用当前状态和即将执行的动作块计算未来的执行时刻状态,并将其与当前环境观测一起输入模型。
- 偏移微调:在训练过程中,固定环境观测,随机采样时间偏移量来构造状态-动作对,迫使模型关注机器人状态输入而非仅依赖视觉特征。
- 共享观测注意力:将一个共享观测与多个偏移分支打包成单一序列,使用块稀疏自注意力掩码,在一次前向传播中完成多分支训练,显著提升了训练效率。
Card 05
数据集与资源
数据集与资源
- 仿真基准:Kinetix(动态操作任务)、LIBERO(包含 Spatial, Object, Goal, LIBERO-10 四个子集)。
- 真实机器人:Galaxea R1 Lite 双臂机器人、LeRobot SO-101 6自由度机械臂。
- 评估模型:$\pi_{0.5}$ 和 SmolVLA-450M。
- 硬件资源:使用笔记本电脑 RTX 4090 进行推理测试,使用 RTX 5090、RTX 5070 测试延迟,使用 4x H100 GPUs 进行模型微调。
Card 06
评估与结果
评估与结果
- 仿真评估:在 Kinetix 基准上,相比于朴素异步推理,准确率提升了 30.5%;在 LIBERO 基准上,实现了最高 1.47x 的加速,同时保持了与同步推理相当的精度。
- 真实世界评估:在抓取放置、堆叠、分类任务中,VLASH 实现了平均 94% 的得分率(高于同步推理的 83%),并达到了最高 2.03x 的加速。
- 反应速度:相比于同步推理,最大反应延迟降低了 17.4x,成功实现了机器人与人类进行乒乓球对打的高动态交互演示。