一眼看懂
封面预览
论文探索了机器人操作中一个重要但未被充分研究的任务:循环操作,即机器人需要执行具有预期终止时间的循环或重复动作。
- 论文探索了机器人操作中一个重要但未被充分研究的任务:循环操作,即机器人需要执行具有预期终止时间的循环或重复动作。
- 核心问题是现有模仿学习方法因无法有效利用历史信息而导致任务失败,且缺乏充足数据和自动评估工具的基准。
- 论文提出了 CycleManip 框架以实现端到端的循环任务操作,并引入了一个包含多样化任务和自动评估方法的基准。
Card 01
研究单位
研究单位
- 中山大学
- 香港中文大学(深圳)
Card 02
论文概述
论文概述
- 论文探索了机器人操作中一个重要但未被充分研究的任务:循环操作,即机器人需要执行具有预期终止时间的循环或重复动作。
- 核心问题是现有模仿学习方法因无法有效利用历史信息而导致任务失败,且缺乏充足数据和自动评估工具的基准。
- 论文提出了 CycleManip 框架以实现端到端的循环任务操作,并引入了一个包含多样化任务和自动评估方法的基准。
Card 03
核心贡献
核心贡献
- 提出了 CycleManip 框架,通过有效的历史感知和理解实现端到端的循环任务操作,无需额外模型、分层结构或大量计算开销。
- 引入了一种成本感知采样策略以高效扩展观察范围,以及一种多任务学习目标以增强策略对循环进度的理解。
- 构建了 CycleManip 基准,提供多样化的循环任务、自动化数据生成流水线和自动评估工具。
- 框架展示了强大的适应性,在通用操作任务上表现良好,并能以即插即用方式集成到 VLA 等模仿策略中。
Card 04
方法描述
方法描述
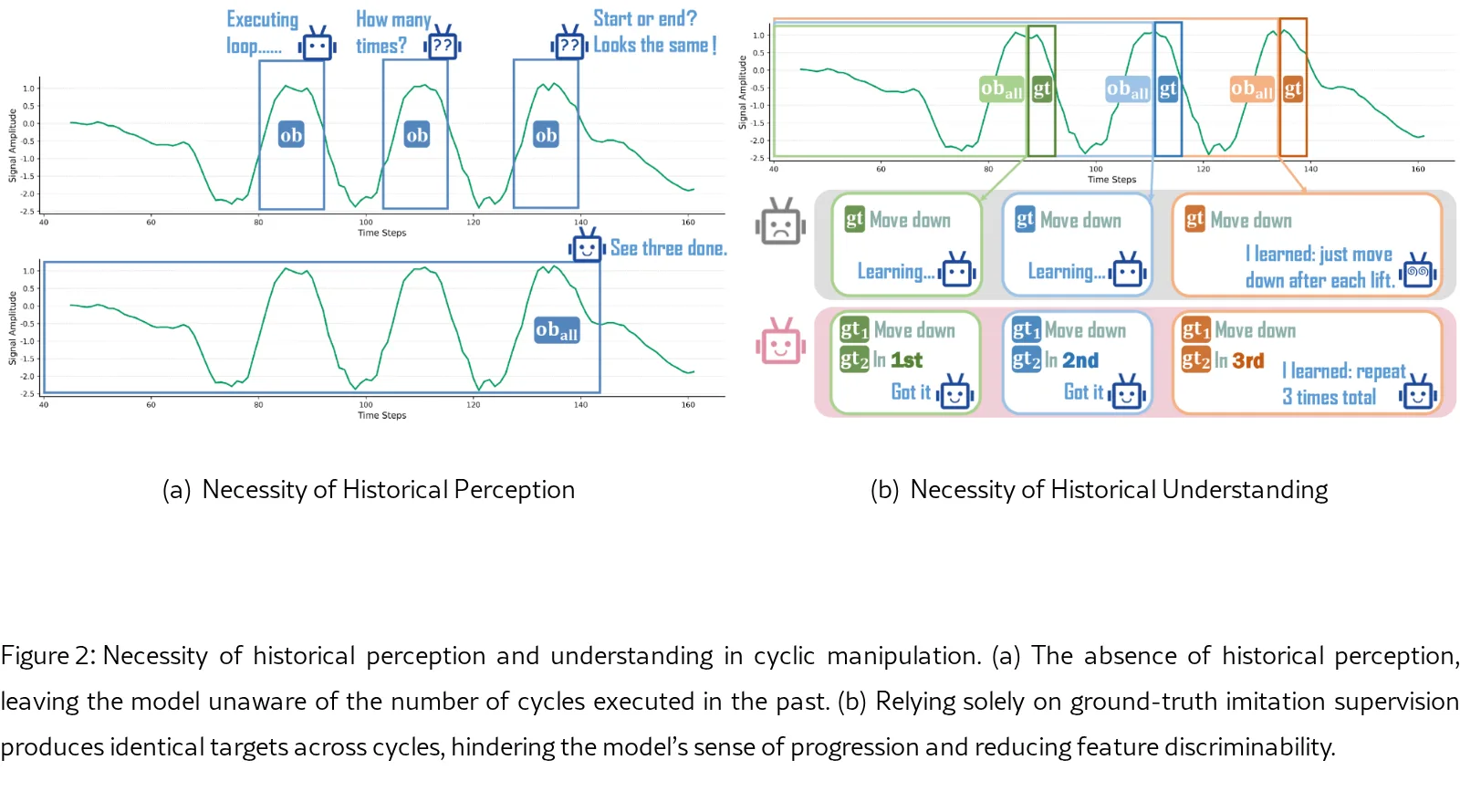
- 框架包含两个核心组件:有效历史感知和有效历史理解。
- 历史感知采用成本感知采样:对高开销视觉观测采用启发式稀疏采样,对低开销本体感知(如末端执行器姿态差)采用密集采样,以低成本扩展时序范围。
- 历史理解通过多任务学习实现,引入一个辅助任务来预测当前的任务进度(循环阶段),从而鼓励模型学习具有进度辨别性的特征。
- 整体框架基于扩散模型,将语言指令和采样后的观测特征作为条件来预测机器人动作。
Card 05
数据集与资源
数据集与资源
- 使用了自建的 CycleManip Benchmark,基于 RoboTwin 2.0 仿真平台构建。
- 基准包含 8 种循环操作任务,每个任务收集了 200 条专家演示轨迹,循环次数范围为 1 到 8 次。
- 模型训练使用单个 RTX 4090 GPU,真实世界推理使用单个 RTX 4070 GPU。
Card 06
评估与结果
评估与结果
- 评估环境包括 CycleManip Benchmark(仿真)、RoboTwin 2.0 Benchmark(通用操作)以及多种真实机器人平台。
- 主要评估指标为 成功率 和 循环次数偏差。
- 在仿真和真实实验中,该方法显著优于 DP、DP3、RDT、Pi-0 等最先进方法,实现了更高的成功率和更低的循环次数偏差。
- 消融实验证明了历史感知与理解模块的有效性。方法在通用操作任务上也取得了最佳性能,并能即插即用地提升 Pi-0 等模型的性能。