一眼看懂
封面预览
论文提出了 MM-ACT,一个统一的视觉-语言-动作模型,旨在解决通用机器人策略所需的语义理解与环境交互预测能力。
- 论文提出了 MM-ACT,一个统一的视觉-语言-动作模型,旨在解决通用机器人策略所需的语义理解与环境交互预测能力。
- 该模型将文本、图像和动作整合在共享的离散令牌空间中,并通过并行解码策略跨三种模态进行生成。
- 论文的核心目标是弥合传统视觉-语言模型缺乏物理动态建模与世界模型缺乏任务规划能力之间的差距。
Card 01
研究单位
研究单位
- 上海人工智能实验室
- 上海交通大学
- 香港大学
- 中国科学技术大学
- 复旦大学
- 浙江大学
Card 02
论文概述
论文概述
- 论文提出了 MM-ACT,一个统一的视觉-语言-动作模型,旨在解决通用机器人策略所需的语义理解与环境交互预测能力。
- 该模型将文本、图像和动作整合在共享的离散令牌空间中,并通过并行解码策略跨三种模态进行生成。
- 论文的核心目标是弥合传统视觉-语言模型缺乏物理动态建模与世界模型缺乏任务规划能力之间的差距。
Card 03
核心贡献
核心贡献
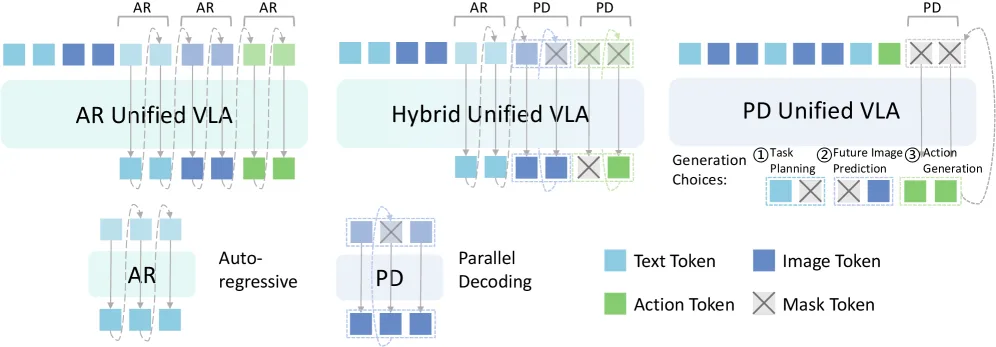
- 提出了一个统一的VLA模型架构,采用并行解码策略统一处理文本、图像和动作三种模态的生成。
- 引入了 Context-Shared Multimodal Learning 训练范式,从共享上下文中监督所有模态的生成,通过跨模态学习增强动作生成能力。
- 为不同模态设计了高效的解码策略:对文本和图像采用重掩码并行解码,对动作采用单步并行解码以实现低延迟推理。
- 在模拟和真实机器人基准测试中均取得了领先的性能,并验证了跨模态学习对动作生成的显著提升。
Card 04
方法描述
方法描述
- 模型基于Transformer架构,配备双向注意力机制,作为一个块级掩码令牌预测器工作。
- 使用模态特定的分词器将文本、图像和机器人状态转换为统一的离散令牌序列。文本使用LLaDA分词器,图像使用Show-o的预训练量化器,动作使用bin分词器。
- 创新点在于采用统一的并行解码建模目标,避免了传统方法中自回归文本生成与扩散式图像/动作生成目标不一致的问题。
- 训练分为两阶段:第一阶段专注于文本和图像生成;第二阶段引入动作生成,并通过调整损失权重维持文本和图像的生成能力。
Card 05
数据集与资源
数据集与资源
- 使用了 LIBERO 仿真基准(包含四个子基准)和 RoboTwin2.0 仿真基准进行评估。
- 在真实的 Franka 机器人平台上进行了三个任务的实验。
- 模型权重从 MMaDA 的基础权重直接训练而来。
- 训练资源未在提供的内容中明确提及。
Card 06
评估与结果
评估与结果
- 评估环境包括模拟基准和真实机器人设置。
- 主要评估指标为任务成功率。
- 关键结果:在 LIBERO 基准上平均成功率达到 96.3%;在 Franka 真实机器人三个任务上平均成功率为 72.0%;在 RoboTwin2.0 八个双臂任务上平均成功率为 52.38%。
- 通过Context-Shared Multimodal Learning,动作生成性能相比仅训练动作的基线提升了 9.25%。消融研究验证了不同解码策略的效果以及机器人状态在上下文中的作用。