一眼看懂
封面预览
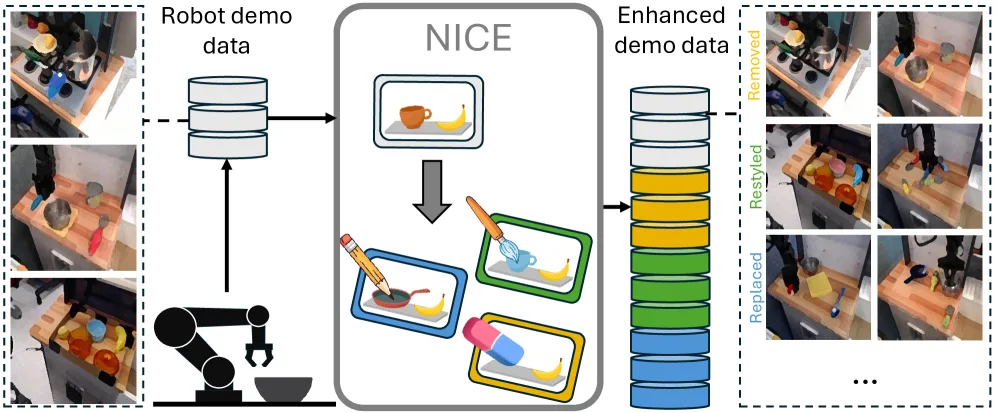
论文提出了 NICE (Naturalistic Inpainting for Context Enhancement) 框架,通过场景手术对…
- 论文提出了 NICE (Naturalistic Inpainting for Context Enhancement) 框架,通过场景手术对…
- 核心目标是解决模仿学习中的分布外 (OOD) 问题,通过引入多样化的视觉干扰物来缩小训练与现实环境之间的视觉差异。
- 该方法无需额外的数据采集、模拟器访问或自定义模型训练,可直接应用于现有的机器人数据集。
Card 01
研究单位
研究单位
- 华为加拿大技术有限公司
Card 02
论文概述
论文概述
- 论文提出了 NICE (Naturalistic Inpainting for Context Enhancement) 框架,通过场景手术对现有机器人演示数据进行增强,以提高视觉运动策略对视觉干扰物的鲁棒性。
- 核心目标是解决模仿学习中的分布外 (OOD) 问题,通过引入多样化的视觉干扰物来缩小训练与现实环境之间的视觉差异。
- 该方法无需额外的数据采集、模拟器访问或自定义模型训练,可直接应用于现有的机器人数据集。
Card 03
核心贡献
核心贡献
- 提出了 NICE 框架,这是一种新颖的数据增强方法,通过对象移除、重样式和替换三种编辑操作,系统地增加场景级视觉多样性。
- 对生成的增强数据进行了全面的真实感评估,包括背景一致性和整体生成质量,并与真实世界样本进行了对比。
- 验证了增强数据在空间可供性预测任务中的有效性,在高度杂乱场景中准确率提升超过20%。
- 通过大规模真实世界机器人操作实验,证明了该方法能将策略成功率平均提高11%,同时降低碰撞率和目标混淆率。
Card 04
方法描述
方法描述
- NICE 框架首先使用 Florence-2 进行对象检测,再利用 SAM-2 进行精确分割,实现场景分解与角色(目标/干扰物)分配。
- 对干扰物执行三种编辑操作:移除 (使用 LaMa 图像修复模型)、重样式 (应用 DTD 数据集纹理) 和 替换 (使用 Stable Diffusion 修复模型,并由 Deepseek-r1:7b 生成提示词)。
- 创新点在于保持空间关系和动作标签一致性的前提下,直接对真实演示图像进行操作,生成逼真的新场景。
Card 05
数据集与资源
数据集与资源
- 使用了 BridgeData 数据集进行方法展示和部分评估。
- 下游任务评估使用了 RoboPoint 视觉语言模型和 π₀ 视觉语言动作模型。
- 纹理采样使用了 Describable Textures Dataset (DTD)。
- 在真实世界机器人上进行了864次试验的评估。
Card 06
评估与结果
评估与结果
- 在 背景一致性 和 生成真实感 方面,SSIM和FID指标表明NICE生成的图像与真实图像高度相似。
- 在 空间可供性预测 任务中,使用 RoboPoint 模型进行评估,结果显示在高杂乱场景中平均预测准确率提升达21.36%。
- 在 机器人操作任务 中,微调 π₀ 模型并评估四种核心技能。使用NICE数据训练的策略,其成功率平均提升11%,碰撞率降低7%,目标混淆率降低6%。