一眼看懂
封面预览
本文提出了 CoT4AD,一个用于端到端自动驾驶的新型视觉-语言-动作模型框架。
- 本文提出了 CoT4AD,一个用于端到端自动驾驶的新型视觉-语言-动作模型框架。
- 该框架通过引入显式的 思维链推理,增强了视觉语言模型在复杂驾驶场景中的数值推理与因果推理能力。
- 论文旨在解决现有VLA模型数值推理能力有限、输入-输出映射过于简化,从而导致在需要逐步因果推理的复杂环境中表现不佳的问题。
Card 01
研究单位
研究单位
- 北京大学
Card 02
论文概述
论文概述
- 本文提出了 CoT4AD,一个用于端到端自动驾驶的新型视觉-语言-动作模型框架。
- 该框架通过引入显式的 思维链推理,增强了视觉语言模型在复杂驾驶场景中的数值推理与因果推理能力。
- 论文旨在解决现有VLA模型数值推理能力有限、输入-输出映射过于简化,从而导致在需要逐步因果推理的复杂环境中表现不佳的问题。
Card 03
核心贡献
核心贡献
- 提出了 CoT4AD,一个端到端自动驾驶框架,它通过多步骤微调预训练VLM,实现了从原始视觉观察和语言指令进行思维链推理和多任务处理。
- 引入了一种创新的、基于扩散的未来场景预测与轨迹规划方法,并将其无缝集成到思维链推理流水线中。
- 在 NuScenes 和 Bench2Drive 数据集上的广泛实验表明,CoT4AD在开环和闭环评估中均建立了新的最先进结果,持续超越先前的LLM驱动和端到端自动驾驶方法。
Card 04
方法描述
方法描述
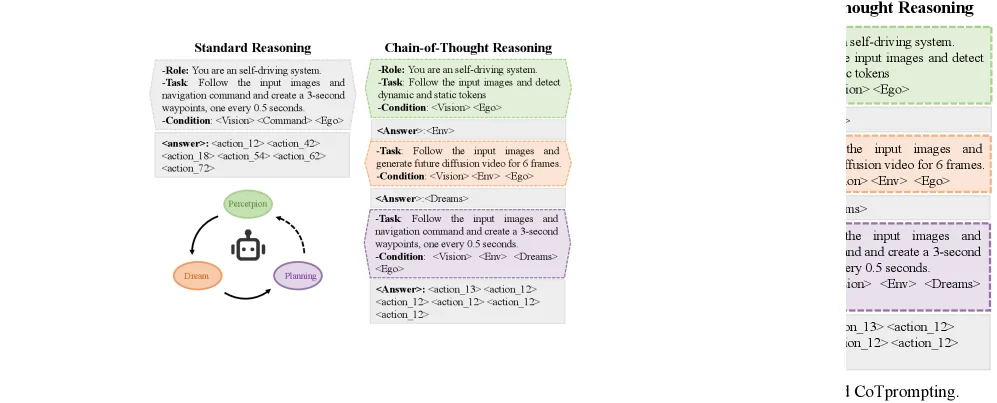
- 提出了一个四阶段的思维链推理流程:3D环境感知、视觉-语言提示调优、VLM条件潜在扩散和思维链轨迹规划。
- 在感知阶段,采用以特征为中心的训练,结合 MapTokenizer、ObjectTokenizer 和 BEVTokenizer 生成包含静态元素、动态对象和整体环境的全面3D视觉标记。
- 在调优阶段,引入可学习的阶段无关标记 Vs 进行软提示调优,并通过视觉问答数据集对模型进行指令微调,以实现从多模态标记到数值推理空间的迁移。
- 创新性地使用一个 VLM条件的潜在扩散模型 来生成高保真的未来场景预测,使模型学习对未来场景变化的视觉推理,增强对环境语义和物理规律的理解。
- 在规划阶段,采用VLM条件的扩散规划器,直接生成轨迹规划,并在推理时可通过隐式思维链在单次前向传播中完成,平衡了规划性能与计算效率。
Card 05
数据集与资源
数据集与资源
- 使用了真实世界数据集 nuScenes 和仿真数据集 Bench2Drive 进行训练和评估。
- 模型基于 LLaMA-3,视觉编码器采用预训练的 EVA-CLIP。
- 训练在8块 NVIDIA RTX A800 GPU(80GB显存)上进行,使用SGD优化器。
Card 06
评估与结果
评估与结果
- 在 NuScenes 开环评估中,CoT4AD 在1s、2s、3s预测范围的L2误差上达到 0.29 m 平均值,碰撞率为 0.10%,显著优于现有最先进的VLA和E2E-AD方法。
- 在 Bench2Drive 闭环评估中,CoT4AD-CoT 取得了最高的驾驶分数 81.22 和成功率 55.78%,超越了包括ORION和DriveTransformer在内的强大基线。
- 消融实验验证了感知分词器、VQA推理模块和未来场景预测模块的有效性,其中未来预测模块对性能提升贡献最大。