一眼看懂
封面预览
论文提出了 DualVLA,旨在解决视觉-语言-动作(VLA)模型在从专家模型向推理模型转换过程中出现的 动作退化 问题。
- 论文提出了 DualVLA,旨在解决视觉-语言-动作(VLA)模型在从专家模型向推理模型转换过程中出现的 动作退化 问题。
- 研究目标是在增强模型多模态推理能力的同时,保持甚至提升其动作执行的准确性和流畅性。
- 为了填补通用 VLA 模型评估的空白,论文还提出了 VLA Score,一种细粒度的评估框架。
Card 01
研究单位
研究单位
- 中国科学技术大学 (University of Science and Technology of China)
- 北京大学 (Peking University)
- 香港中文大学 (The Chinese University of Hong Kong)
Card 02
论文概述
论文概述
- 论文提出了 DualVLA,旨在解决视觉-语言-动作(VLA)模型在从专家模型向推理模型转换过程中出现的 动作退化 问题。
- 研究目标是在增强模型多模态推理能力的同时,保持甚至提升其动作执行的准确性和流畅性。
- 为了填补通用 VLA 模型评估的空白,论文还提出了 VLA Score,一种细粒度的评估框架。
Card 03
核心贡献
核心贡献
- 提出了 DualVLA 框架,通过数据剪枝和双教师自适应蒸馏策略,在数据和损失层面解耦推理与动作学习。
- 设计了 双层推理剪枝 策略,利用视频事件预测和运动学线索去除冗余的低熵推理数据,构建稀疏且信息密集的数据集。
- 引入了 双教师自适应蒸馏 策略,利用专家 VLA 作为动作教师提供细粒度监督,利用初始 VLA 作为推理教师保持通用能力。
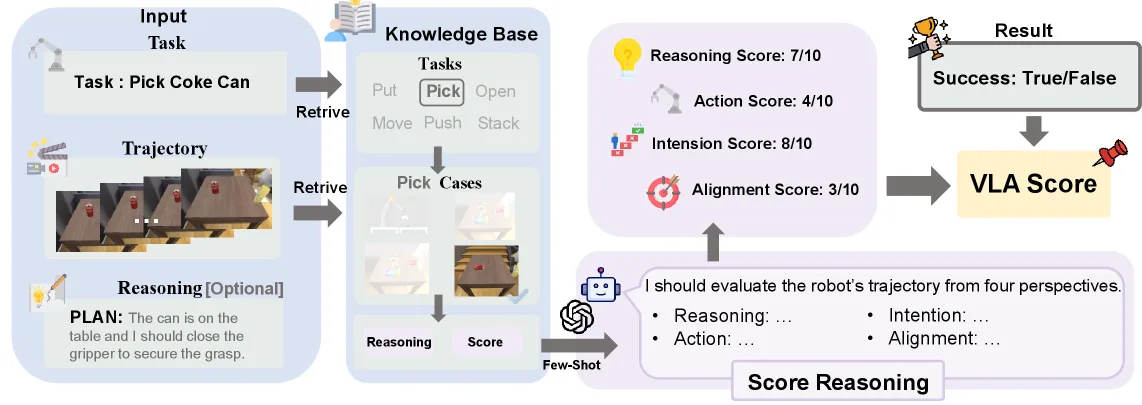
- 提出了 VLA Score,首个针对推理型 VLA 的评估框架,利用 VLM(如 GPT-4o)作为评判者,从推理、意图、动作和对齐四个维度进行评估。
Card 04
方法描述
方法描述
- 双层推理剪枝:结合场景事件边界检测(使用重训练的 DDM-Net)和运动学关键帧选择(基于末端执行器速度和夹爪状态变化),仅保留同时满足场景和动作关键帧标准的推理内容,过滤掉对动作学习有负面影响的重复推理。
- 双教师自适应蒸馏:针对机器人数据和多模态数据分别设计蒸馏损失。机器人数据使用 动作教师(InstructVLA-E)的软标签监督以提升操作能力;多模态数据使用 推理教师(InstructVLA-G 初始化权重)的软标签监督以保持推理能力。
- VLA Score 评估流程:使用 GPT-4o 作为评判模型,采用双检索机制(任务检索和场景检索)增强上下文,计算推理、意图、动作和对齐分数并综合得出最终评分。
Card 05
数据集与资源
数据集与资源
- 数据集:重构的 VLA-IT 数据集(650k 样本)、SimplerEnv 仿真基准、自采集的真实世界双臂机器人演示数据。
- 模型规模:基于 InstructVLA-G 进行微调,动作教师为 InstructVLA-E。
- 训练资源:学习率固定为 2e-5,具体 GPU/TPU 数量原文未明确提及。
Card 06
评估与结果
评估与结果
- 评估环境:SimplerEnv 仿真环境(包含 Google Robot 和 WidowX 两种形态)、真实世界 Galaxea R1-lite 双臂机器人平台。
- 主要指标:成功率、VLA Score、多模态基准测试平均分。
- 关键结果:
- 在 SimplerEnv 上实现了 61.0% 的平均成功率,优于基线模型 InstructVLA-G 和其他专家/推理 VLA 模型。
- 在 8 个多模态基准测试中取得了 65.4 的平均分,展示了良好的推理与动作平衡能力。
- 真实世界实验中,平均成功率从基线的 45% 提升至 60%。
- VLA Score 评估显示 DualVLA 在推理、动作和对齐维度上均优于其他推理型 VLA 模型。