一眼看懂
封面预览
提出了 ADVLA 框架,这是一种针对 Vision-Language-Action (VLA) 模型的注意力引导、补丁级稀疏对抗攻击方法。
- 提出了 ADVLA 框架,这是一种针对 Vision-Language-Action (VLA) 模型的注意力引导、补丁级稀疏对抗攻击方法。
- 旨在解决现有攻击方法需要高昂的端到端训练成本以及生成的对抗补丁视觉上过于显眼的问题。
- 通过直接在视觉编码器投影到的文本特征空间施加对抗扰动,实现了在低幅度约束下高效破坏下游动作预测的目标。
Card 01
研究单位
研究单位
- 提供的 HTML 文本片段中未包含作者所属的具体研究机构信息。
Card 02
论文概述
论文概述
- 提出了 ADVLA 框架,这是一种针对 Vision-Language-Action (VLA) 模型的注意力引导、补丁级稀疏对抗攻击方法。
- 旨在解决现有攻击方法需要高昂的端到端训练成本以及生成的对抗补丁视觉上过于显眼的问题。
- 通过直接在视觉编码器投影到的文本特征空间施加对抗扰动,实现了在低幅度约束下高效破坏下游动作预测的目标。
Card 03
核心贡献
核心贡献
- 提出了针对 VLA 模型视觉特征空间的灰盒攻击框架 ADVLA,避免了传统方法的高昂训练成本。
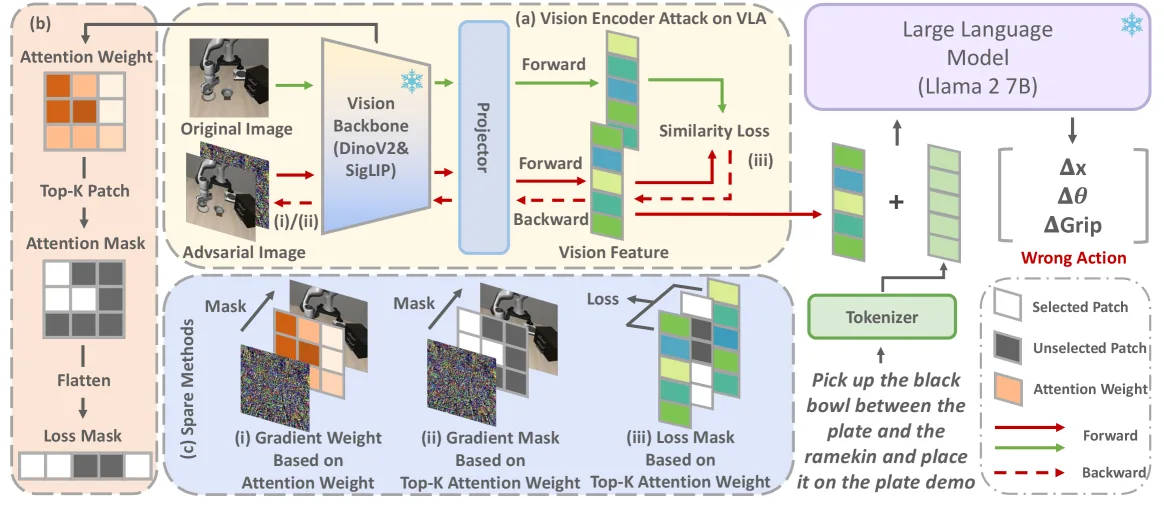
- 设计了三种独立的注意力引导策略:注意力加权梯度 (ADVLA-AW)、Top-K 掩码梯度 (ADVLA-TKM) 和 Top-K 损失 (ADVLA-TKL),以实现高效、稀疏且不可感知的攻击。
- 实验证明,该方法在严格的扰动约束下实现了近 100% 的攻击成功率,且单步迭代仅需约 0.06 秒,显著优于传统的补丁攻击方法。
Card 04
方法描述
方法描述
- 采用 灰盒攻击设定,假设攻击者可以访问视觉编码器(如 DinoV2 和 SigLIP)及其投影层的参数和梯度,但无法访问下游 LLM。
- 基础攻击方法利用 投影梯度下降 (PGD) 算法,通过最小化干净图像特征与对抗图像特征在文本对齐空间中的余弦相似度来生成扰动。
- 引入注意力机制指导扰动生成:ADVLA-AW 利用注意力权重加权梯度;ADVLA-TKM 通过 Top-K 掩码限制仅在关键补丁上更新梯度以实现稀疏性;ADVLA-TKL 仅计算关键补丁特征的损失以聚焦敏感区域。
Card 05
数据集与资源
数据集与资源
- 使用的数据集为 LIBERO 基准数据集,包含 Spatial、Object、Goal 和 Long 四个任务套件。
- 受害模型选用 OpenVLA 模型的四个独立训练变体。
- 实验硬件资源为单张 NVIDIA H100 GPU,攻击单个样本的峰值内存使用量约为 17GB。
Card 06
评估与结果
评估与结果
- 在 LIBERO 仿真环境中进行评估,主要指标为 失败率。
- 在 L_inf = 4/255 的约束下,ADVLA 及其变体在所有任务套件上的平均失败率接近 100%,效果与基线方法 UADA 相当。
- ADVLA-TKM 策略仅需修改不到 10% 的图像补丁即可达到接近 100% 的攻击成功率,且扰动在视觉上几乎不可见。
- 相比 UADA 需要约 15 小时生成补丁,ADVLA 单步迭代仅需约 0.06 秒,实现了数量级的加速。