一眼看懂
封面预览
提出 EchoVLA,一种用于移动操作的内存感知 视觉-语言-动作(VLA) 模型,旨在解决现有VLA模型局限于短视野桌面操作的问题。
- 提出 EchoVLA,一种用于移动操作的内存感知 视觉-语言-动作(VLA) 模型,旨在解决现有VLA模型局限于短视野桌面操作的问题。
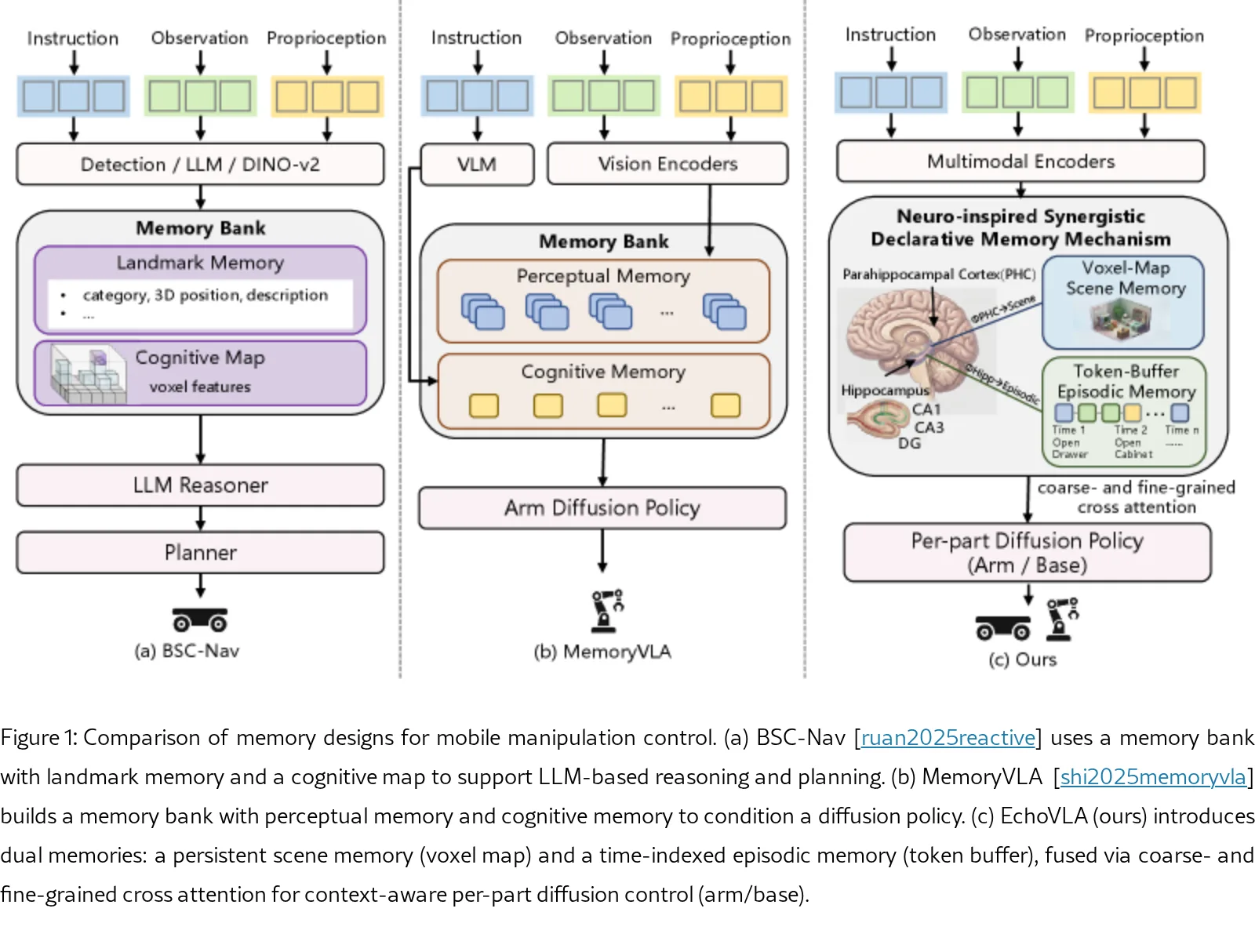
- 模型受人类大脑陈述性记忆系统启发,引入协同的 场景记忆 和 情景记忆,以维持空间上下文一致性并跟踪任务进度。
- 解决了在动态空间环境中,移动机器人需要协调导航与操作动作的核心挑战。
Card 01
研究单位
研究单位
- 中山大学深圳校区(Shenzhen Campus of Sun Yat-sen University)
- 上海交通大学(Shanghai Jiao Tong University)
- 华为诺亚方舟实验室(Huawei Noah’s Ark Lab)
Card 02
论文概述
论文概述
- 提出 EchoVLA,一种用于移动操作的内存感知 视觉-语言-动作(VLA) 模型,旨在解决现有VLA模型局限于短视野桌面操作的问题。
- 模型受人类大脑陈述性记忆系统启发,引入协同的 场景记忆 和 情景记忆,以维持空间上下文一致性并跟踪任务进度。
- 解决了在动态空间环境中,移动机器人需要协调导航与操作动作的核心挑战。
Card 03
核心贡献
核心贡献
- 提出 EchoVLA,一个具有协同场景记忆与情景记忆的神经启发式内存感知VLA模型。
- 引入 MoMani,一个自动化基准,通过 MLLM引导规划 和 反馈驱动优化 生成专家级轨迹,并补充了真实机器人演示数据。
- 在仿真和真实世界环境中进行了广泛验证,证明EchoVLA在各类移动操作任务上持续优于强基线模型。
Card 04
方法描述
方法描述
- 双重记忆机制:场景记忆 维护一个持久的体素化3D特征地图,表示环境的空间结构;情景记忆 以时间索引方式存储近期多模态标记序列,跟踪细粒度任务进展。
- 分层记忆检索:使用 粗粒度 和 细粒度 交叉注意力机制,分别从场景记忆和情景记忆中检索相关信息并融合。
- 部分扩散策略:为移动底座和机械臂设计独立的去噪扩散过程,实现结构化且解耦的动作生成,支持协调的运动与操作行为学习。
Card 05
数据集与资源
数据集与资源
- MoMani 数据集:包含 7,889条仿真轨迹(涵盖导航与移动操作任务)和 1,200条真实机器人演示(在TidyBot++平台上收集)。
- 模型训练:在 8块NVIDIA A100 GPU 上进行训练。
- 数据规模:仿真数据包含 5,000+ 条高质量多模态轨迹。
Card 06
评估与结果
评估与结果
- 评估环境:在 RoboCasa仿真器 和 TidyBot++真实机器人平台(在7m×7m场地内)上进行评估。
- 主要指标:成功率。
- 关键结果:
- 在仿真中,EchoVLA在操作/导航任务和移动操作任务上分别达到 0.52 和 0.31 的最高成功率,显著超越强基线 π₀.₅(分别高出+0.20和+0.11)。
- 在真实世界实验中,EchoVLA平均成功率达到 0.44,优于 π₀.₅(0.33)和 扩散策略(0.32)。