一眼看懂
封面预览
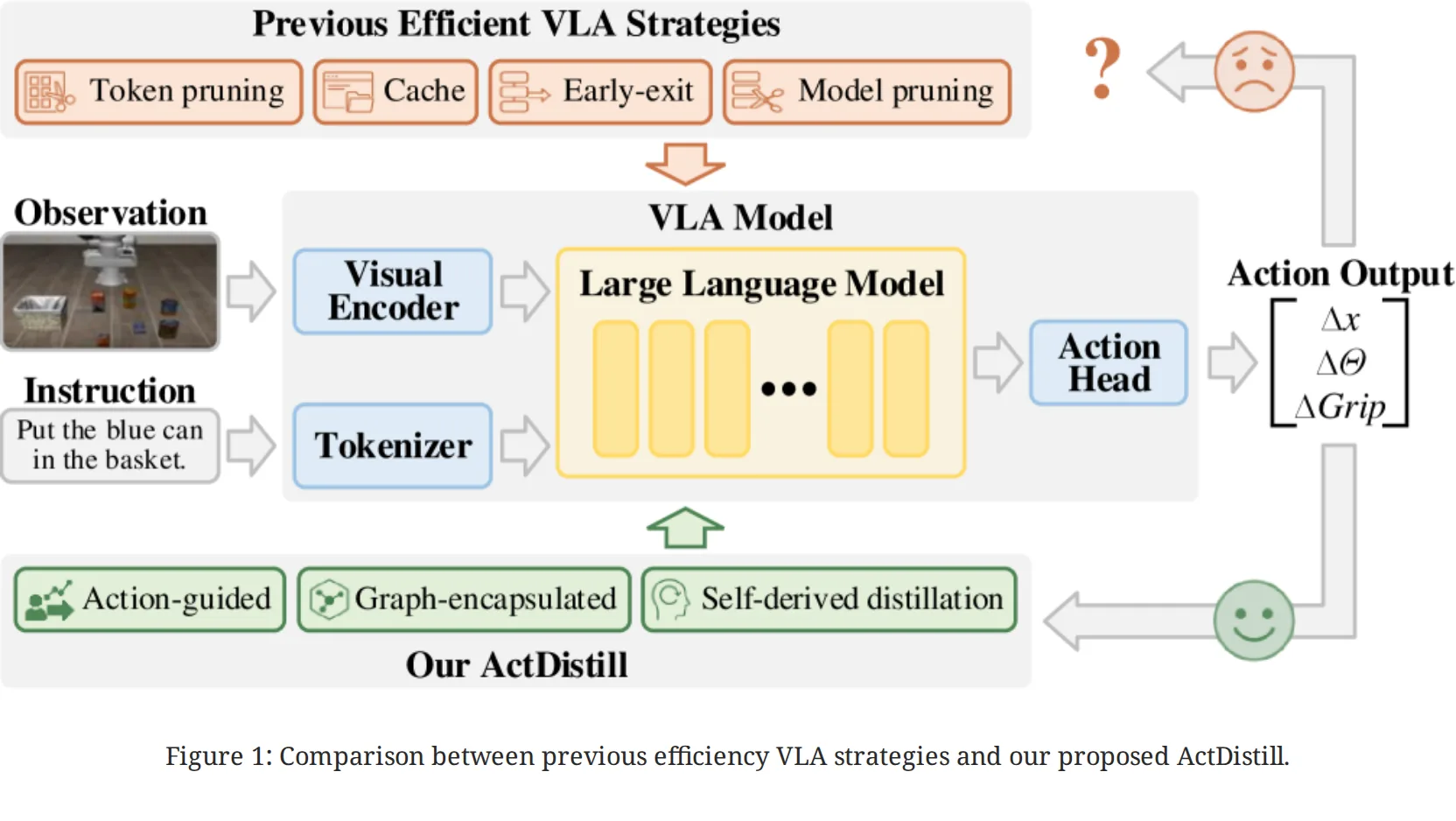
论文针对 Vision-Language-Action (VLA) 模型在实际部署中面临的计算开销大和推理延迟高的问题,提出了 ActDist…
- 论文针对 Vision-Language-Action (VLA) 模型在实际部署中面临的计算开销大和推理延迟高的问题,提出了 ActDist…
- 旨在通过 动作引导的自蒸馏 方法,将大规模 VLA 教师模型的能力迁移到轻量级学生模型上,实现高效的具身智能推理。
- 解决了现有方法忽视视觉-语言到动作的渐进式转换过程,导致关键动作信息丢失和语义不连续的问题。
Card 01
研究单位
研究单位
- 同济大学
- 悉尼科技大学
- 大数据高级研究院
Card 02
论文概述
论文概述
- 论文针对 Vision-Language-Action (VLA) 模型在实际部署中面临的计算开销大和推理延迟高的问题,提出了 ActDistill 框架。
- 旨在通过 动作引导的自蒸馏 方法,将大规模 VLA 教师模型的能力迁移到轻量级学生模型上,实现高效的具身智能推理。
- 解决了现有方法忽视视觉-语言到动作的渐进式转换过程,导致关键动作信息丢失和语义不连续的问题。
Card 03
核心贡献
核心贡献
- 提出了 ActDistill,一种通用的动作引导蒸馏框架,首次将模型压缩显式地与 VL-to-Action 转换过程对齐。
- 引入了 图结构封装 技术,利用 K 近邻图和注意力机制建模动作预测中的层次化依赖关系,提取动作中心的语义胶囊。
- 设计了 动作引导的动态路由 机制,根据动作需求自适应地选择关键计算层,跳过冗余层以提升效率。
- 在多个具身智能基准测试中,实现了计算量减少超过 50% 且推理速度提升最高达 1.67倍,同时保持了与原模型相当的性能。
Card 04
方法描述
方法描述
- 教师模型处理:采用图结构封装技术,将中间层特征构建为动态关系图,通过注意力池化生成结构化语义嵌入(Semantic Capsules),并使用辅助损失函数对其进行动作预测监督。
- 学生模型构建:设计了一个包含 动态路由器 的轻量级副本,路由器根据输入的视觉和语言嵌入计算层级门控分数,决定执行或跳过特定层。
- 蒸馏训练:结合语义对齐损失、动作一致性损失和负载均衡损失,引导学生模型重建教师的层级控制推理过程,同时学习路由策略。
- 推理过程:推理时仅保留学生模型和路由器,根据阈值选择性执行关键层,大幅降低计算成本。
Card 05
数据集与资源
数据集与资源
- 训练数据集:使用 Open X-Embodiment 数据集中的 Berkeley Bridge 子集进行训练。
- 评估基准:在 LIBERO(包含 Spatial, Object, Goal, Long 四个任务套件)和 SIMPLER(包含 Visual Matching 和 Variant Aggregation 场景)基准上进行评估。
- 硬件资源:使用 4 张 NVIDIA RTX 5090 GPU 进行训练,耗时约 8 小时。
Card 06
评估与结果
评估与结果
- 基准模型:在 OpenVLA(自回归范式)和 CogAct(扩散范式)两种代表性 VLA 模型上进行了验证。
- 主要指标:成功率、加速比 和计算量。
- 实验结果:
- 在 LIBERO 基准上,平均成功率为 73.95%(教师模型为 74.95%),实现了 1.59倍 加速,计算量降至 49.50%。
- 在 SIMPLER 基准的 Visual Matching 场景中,平均成功率为 74.08%,实现了 1.67倍 加速,计算量降至 42.30%。
- 相比 VLA-Cache、EfficientVLA、MoLe-VLA 等现有方法,ActDistill 在保持相近精度的同时实现了更高的加速比和更低的计算消耗。