一眼看懂
封面预览
论文提出了 MobileVLA-R1,一个用于四足机器人的统一视觉-语言-行动(VLA)框架,旨在解决将自然语言指令接地到连续控制这一根本挑战。
- 论文提出了 MobileVLA-R1,一个用于四足机器人的统一视觉-语言-行动(VLA)框架,旨在解决将自然语言指令接地到连续控制这一根本挑战。
- 现有方法难以连接高层语义推理与低层执行,导致接地不稳定、泛化能力弱。本文通过引入显式推理和连续控制来解决这些问题。
- 论文的核心目标是构建一个能够实现可解释规划、跨多种环境进行鲁棒控制的具身基础模型。
Card 01
研究单位
研究单位
- 北京大学
Card 02
论文概述
论文概述
- 论文提出了 MobileVLA-R1,一个用于四足机器人的统一视觉-语言-行动(VLA)框架,旨在解决将自然语言指令接地到连续控制这一根本挑战。
- 现有方法难以连接高层语义推理与低层执行,导致接地不稳定、泛化能力弱。本文通过引入显式推理和连续控制来解决这些问题。
- 论文的核心目标是构建一个能够实现可解释规划、跨多种环境进行鲁棒控制的具身基础模型。
Card 03
核心贡献
核心贡献
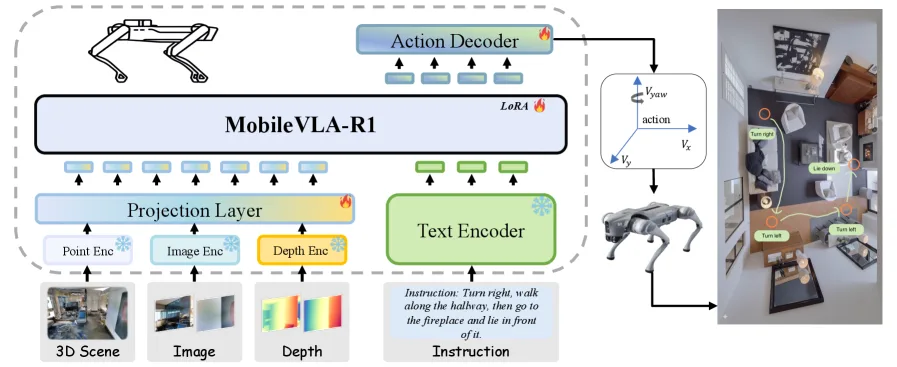
- 提出了 MobileVLA-R1,一种分层VLA框架,通过思维链生成和连续控制,显式连接了语义推理与电机控制。
- 设计了一个结合监督CoT对齐与GRPO强化学习的两阶段训练范式,提升了推理一致性、控制鲁棒性和长程执行稳定性。
- 构建了 MobileVLA-CoT,一个用于具身轨迹的多粒度CoT数据集,并在具身AI基准上实现了约 5% 的性能提升,成功在 Unitree Go2 平台上部署。
Card 04
方法描述
方法描述
- 采用“先推理后执行”的设计,模型先生成结构化CoT动作计划,再通过动作解码器转换为连续控制命令。
- 训练过程分两阶段:第一阶段通过在CoT标注数据上进行监督微调以对齐推理能力;第二阶段通过Group Relative Policy Optimization 强化学习来优化动作接地与执行保真度。
- 模型架构遵循 LLaVA 设计,集成了RGB、深度和点云输入的多模态感知前端,并初始化自 NaVILA 模型。
Card 05
数据集与资源
数据集与资源
- 使用了公开数据集 R2R、RxR 和 QUARD,并合成了大规模思维链语料库 MobileVLA-CoT。
- MobileVLA-CoT 包含三个子集:Episode级(18K)、Step级(78K)和Navigation级(38K)CoT标注。
- 模型基于 LLaMA3-8B 语言主干,并使用 LoRA 进行参数高效调优。
- 监督微调在 4× H20 GPU 上进行,GRPO强化学习在 单张 H20 GPU 上完成。
Card 06
评估与结果
评估与结果
- 在 VLN-CE 和 QUARD 基准上进行了广泛评估。VLN-CE使用 R2R-CE 和 RxR-CE 数据集。
- 主要评估指标包括导航误差(NE)、成功率(SR)、成功加权路径长度(SPL)等。
- 在 VLN-CE Val-Unseen 分割上,MobileVLA-R1取得了最先进性能,平均成功率比强基线提高约 5%。
- 在 QUARD 基准的六项控制任务上,模型在所有难度级别(Easy, Medium, Hard)上均一致超越了基线方法。
- 真实世界部署在 Unitree Go2 四足机器人上完成,在杂乱和部分可观测条件下验证了鲁棒性能。