一眼看懂
封面预览
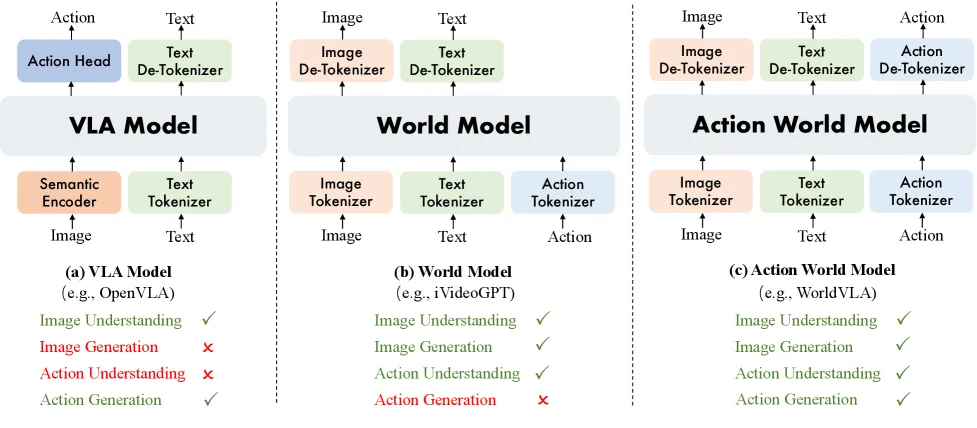
论文提出了 RynnVLA-002,这是一个统一的视觉-语言-动作(VLA)模型与世界模型框架。
- 论文提出了 RynnVLA-002,这是一个统一的视觉-语言-动作(VLA)模型与世界模型框架。
- 该框架旨在解决标准 VLA 模型缺乏对动作的显式理解、想象能力和物理理解的问题,同时弥补世界模型无法直接生成动作的不足。
- 通过联合学习环境动力学和动作规划,VLA 模型与世界模型相互增强,实现了双向的性能提升。
Card 01
研究单位
研究单位
- DAMO Academy, Alibaba Group
- Hupan Lab
- Zhejiang University
Card 02
论文概述
论文概述
- 论文提出了 RynnVLA-002,这是一个统一的视觉-语言-动作(VLA)模型与世界模型框架。
- 该框架旨在解决标准 VLA 模型缺乏对动作的显式理解、想象能力和物理理解的问题,同时弥补世界模型无法直接生成动作的不足。
- 通过联合学习环境动力学和动作规划,VLA 模型与世界模型相互增强,实现了双向的性能提升。
Card 03
核心贡献
核心贡献
- 提出了 RynnVLA-002 统一框架,将 VLA 模型与世界模型整合在单一架构中,实现了动作预测与世界建模能力的互补。
- 针对离散动作块生成中的误差累积问题,设计了一种动作注意力掩码策略;同时引入连续 Action Transformer 头以增强泛化能力和轨迹平滑度。
- 在 LIBERO 仿真基准测试中,无需预训练即达到了 97.4% 的成功率;在真实机器人实验中,集成的世界模型将整体成功率提升了 50%。
Card 04
方法描述
方法描述
- 模型基于 Chameleon 架构初始化,使用统一的词表(大小为 65536)处理图像、文本、状态和动作标记。
- 引入了专门的动作注意力掩码机制,在生成当前动作时屏蔽先前动作,消除自回归生成中的误差传播。
- 为了解决真实机器人任务中的泛化和抖动问题,在离散建模基础上增加了连续 Action Transformer 头,利用并行解码生成更平滑的动作轨迹。
Card 05
数据集与资源
数据集与资源
- 仿真实验使用了 LIBERO 基准数据集,包含 Spatial、Object、Goal 和 Long 四个任务套件。
- 真实世界实验构建了一个新的 LeRobot SO100 机械臂操作数据集,包含“将方块放入圆圈”和“将草莓放入杯子”两个任务。
- 模型输入包括历史图像观测、本体感知状态和语言指令。
Card 06
评估与结果
评估与结果
- 在 LIBERO 仿真基准上,连续动作版本的模型取得了 97.4% 的平均成功率,离散动作版本达到了 93.3%,无需预训练即可媲美甚至超越现有的强基线模型。
- 在真实世界 SO100 机械臂实验中,模型在多目标和干扰物场景下的表现优于 GR00T N1.5 和 $\pi_{0}$ 等基线,成功率高出 10% 至 30%。
- 消融实验表明,世界模型数据对 VLA 模型至关重要,能将真实世界任务的成功率从低于 30% 提升至超过 80%;同时 VLA 数据也增强了世界模型的视频生成质量。