一眼看懂
封面预览
研究目标是解决视觉-语言-动作(VLA)模型中"先思考后行动"(Think-Before-Acting)的范式,让机器人能够在执行动作前进行链…
- 研究目标是解决视觉-语言-动作(VLA)模型中"先思考后行动"(Think-Before-Acting)的范式,让机器人能够在执行动作前进行链…
- 核心问题在于现有方法使用单一自回归解码器同时处理顺序推理和并行的高维动作向量,导致架构不匹配,降低运动控制精度并削弱推理与动作之间的因果联系
- 提出 DeepThinkVLA,通过协同设计模型架构和训练策略来解决这一根本性冲突
Card 01
研究单位
研究单位
- 华中科技大学 - 机械科学与工程学院,中国
- 清华大学 - 计算机科学与技术系,中国
- 中国人民大学 - 高瓴人工智能学院,中国
- 北京中关村学院,中国
Card 02
论文概述
论文概述
- 研究目标是解决视觉-语言-动作(VLA)模型中"先思考后行动"(Think-Before-Acting)的范式,让机器人能够在执行动作前进行链式思考(CoT)推理
- 核心问题在于现有方法使用单一自回归解码器同时处理顺序推理和并行的高维动作向量,导致架构不匹配,降低运动控制精度并削弱推理与动作之间的因果联系
- 提出 DeepThinkVLA,通过协同设计模型架构和训练策略来解决这一根本性冲突
Card 03
核心贡献
核心贡献
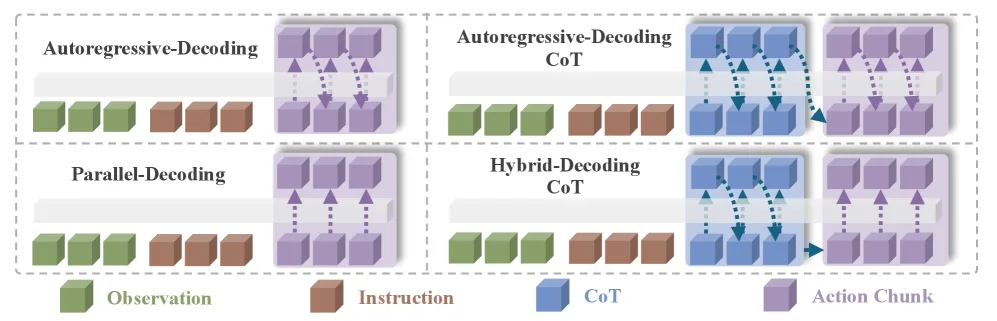
- 提出混合注意力解码器(Hybrid-Attention Decoder),对 CoT 推理使用因果注意力进行自回归生成,对动作生成切换到双向注意力进行并行解码
- 设计两阶段训练管道:首先通过监督微调(SFT)注入基础推理能力,然后使用基于结果的强化学习(RL)对推理-动作序列进行因果对齐
- 开发了自动化数据构建管道,利用云端 VLM 生成关键帧的 CoT 注解,并微调本地 VLM 标注中间帧
- 在 LIBERO 基准上达到 97.0% 的平均成功率,显著超越现有最优方法
Card 04
方法描述
方法描述
- 问题形式化:将策略分解为 P(A,R\|V,L) = P(A\|V,L,R)·P(R\|V,L),引入潜在推理变量 R(链式思考)
- 混合架构:在单一解码器中动态切换注意力模式——CoT 生成阶段使用标准因果自回归注意力,动作生成阶段切换到双向(非因果)注意力实现并行解码
- 训练管道:第一阶段 SFT 在构建的实体 CoT 数据集上进行冷启动训练;第二阶段使用 GRPO 风格的分组信用分配进行在线 RL,利用任务成功奖励信号同时优化推理和动作能力
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 基准,包含四个套件(Object、Spatial、Goal、Long),每个套件 10 个任务
- 基础模型:基于 π₀-FAST 公开权重初始化,2.9B 参数规模
- 评估环境:50 个随机初始条件下评估每个任务,成功率(SR)作为主要指标
Card 06
评估与结果
评估与结果
- 主要结果:DeepThinkVLA 在 LIBERO 基准上达到 97.0% 平均成功率,超越所有基线方法
- 分项表现:Object 99.0%、Spatial 96.6%、Goal 96.4%、Long 96.2%
- 消融实验:混合架构比朴素 AR-CoT 基线提升 15.5 个百分点;RL 阶段额外带来 2 个百分点的提升
- 推理效率:混合架构仅增加 1.4× 延迟(相比基线 4× 延迟),同时保持更高准确性