一眼看懂
封面预览
论文展示了如何在单张消费级 GPU(RTX 4090)上实现 π0-level 多视角 VLA 模型的实时推理,达到 30 FPS 帧率和最高…
- 论文展示了如何在单张消费级 GPU(RTX 4090)上实现 π0-level 多视角 VLA 模型的实时推理,达到 30 FPS 帧率和最高…
- 研究的核心问题是解决大型 VLA 模型在机器人控制中的延迟问题,使动态实时任务(如抓取下落物体)得以实现
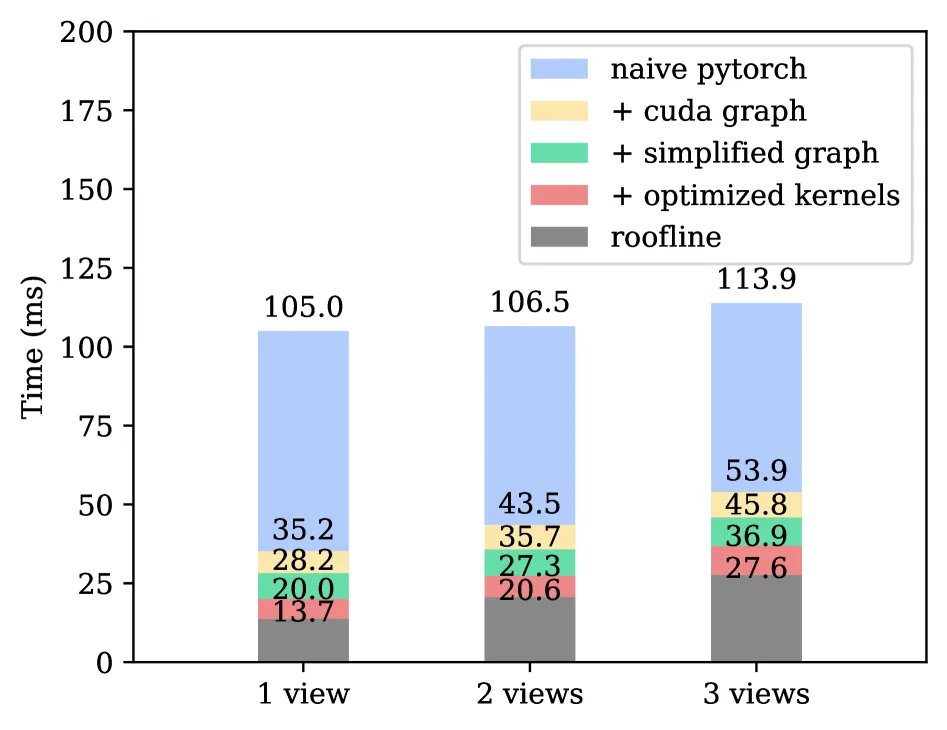
- 通过系统性的工程优化,将推理延迟从 naive torch 的 106.5ms 降低到 27.3ms(双视角),比官方 openpi 实现快近…
Card 01
研究单位
研究单位
- Dexmal(作者:Yunchao Ma, Yunhuan Yang, Tiancai Wang, Haoqiang Fan)
- StepFun(作者:Yizhuang Zhou)
Card 02
论文概述
论文概述
- 论文展示了如何在单张消费级 GPU(RTX 4090)上实现 π0-level 多视角 VLA 模型的实时推理,达到 30 FPS 帧率和最高 480 Hz 轨迹频率
- 研究的核心问题是解决大型 VLA 模型在机器人控制中的延迟问题,使动态实时任务(如抓取下落物体)得以实现
- 通过系统性的工程优化,将推理延迟从 naive torch 的 106.5ms 降低到 27.3ms(双视角),比官方 openpi 实现快近一倍
Card 03
核心贡献
核心贡献
- 使用 CUDA Graph 机制消除 CPU 开销,将内核启动开销从约 13ms 降低到 1.72ms
- 通过计算图简化(层融合、常量折叠、QKV 投影合并)减少冗余计算和内核数量
- 基于 Triton 的 GEMM tile 参数调优、门控线性层融合、Partial Split-k 等深度内核优化
- 提出 Full Streaming Inference 框架,实现 30Hz 视觉循环 + 480Hz 力控制循环的双层反馈架构
- 真实世界验证:在抓取下落笔任务中达到 100% 成功率,端到端反应时间 < 200ms
Card 04
方法描述
方法描述
- CUDA Graph 消除 CPU 开销:记录并重放内核流,去除 Python 执行开销
- 计算图简化:将 RMS Norm 仿射参数融合到后续线性层、折叠 Action Time Encoder、合并 QKV 投影矩阵、RoPE 融合
- 深度内核优化:使用 Triton 自定义 tile 大小、融合门控线性层(FFN 中的 GELU 门控)、Partial Split-k 解决 SM 分布不均、融合标量操作(bias、residual、activation)
- 建立性能下界:使用 Roofline 模型计算理论下限,同步开销通过软件 barrier 估计,分析表明当前实现已接近最优(剩余优化空间 < 30%)
Card 05
数据集与资源
数据集与资源
- 模型:π0 模型(基于 PaliGemma 的 VLM + Action Expert)
- VLM 参数量:3B 参数(SigLIP 400M + Gemma 2.6B)
- Action Expert 参数量:300M 参数
- 训练数据:600 个抓取下落笔的演示 episode
- 硬件:单张 RTX 4090 GPU
- 图像分辨率:240×320(接近目标 224×224)
Card 06
评估与结果
评估与结果
- 推理速度(单 RTX 4090):
- 1 view: 20.0ms(vs naive torch 105ms, openpi 43.8ms)
- 2 views: 27.3ms(vs naive torch 106.5ms, openpi 53.7ms)
- 3 views: 36.8ms(vs naive torch 113.9ms, openpi 67.6ms)
- 性能下界:1 view 13.7ms, 2 views 20.6ms, 3 views 27.6ms(当前实现距最优仅 30%)
- 同步开销:CUDA Graph 下 1.72ms,软件 barrier 下 0.86ms
- 真实世界任务:抓取下落笔,100% 成功率,端到端延迟 < 200ms(与人类反应速度相当)
- Full Streaming 架构:VLM 30Hz + AE 480Hz 可并行运行,总计每秒可处理 30 次 VLM 推理 + 480 次 AE 推理