一眼看懂
封面预览
论文研究了视觉-语言-行动(VLA)模型如何通过真实世界部署中的强化学习(RL)进行自我改进,提出了一个名为 RECAP 的通用方法框架。
- 论文研究了视觉-语言-行动(VLA)模型如何通过真实世界部署中的强化学习(RL)进行自我改进,提出了一个名为 RECAP 的通用方法框架。
- 核心目标是解决VLA模型超越模仿学习、利用自主实践经验进行“练习”以掌握技能、提升鲁棒性和执行速度的问题。
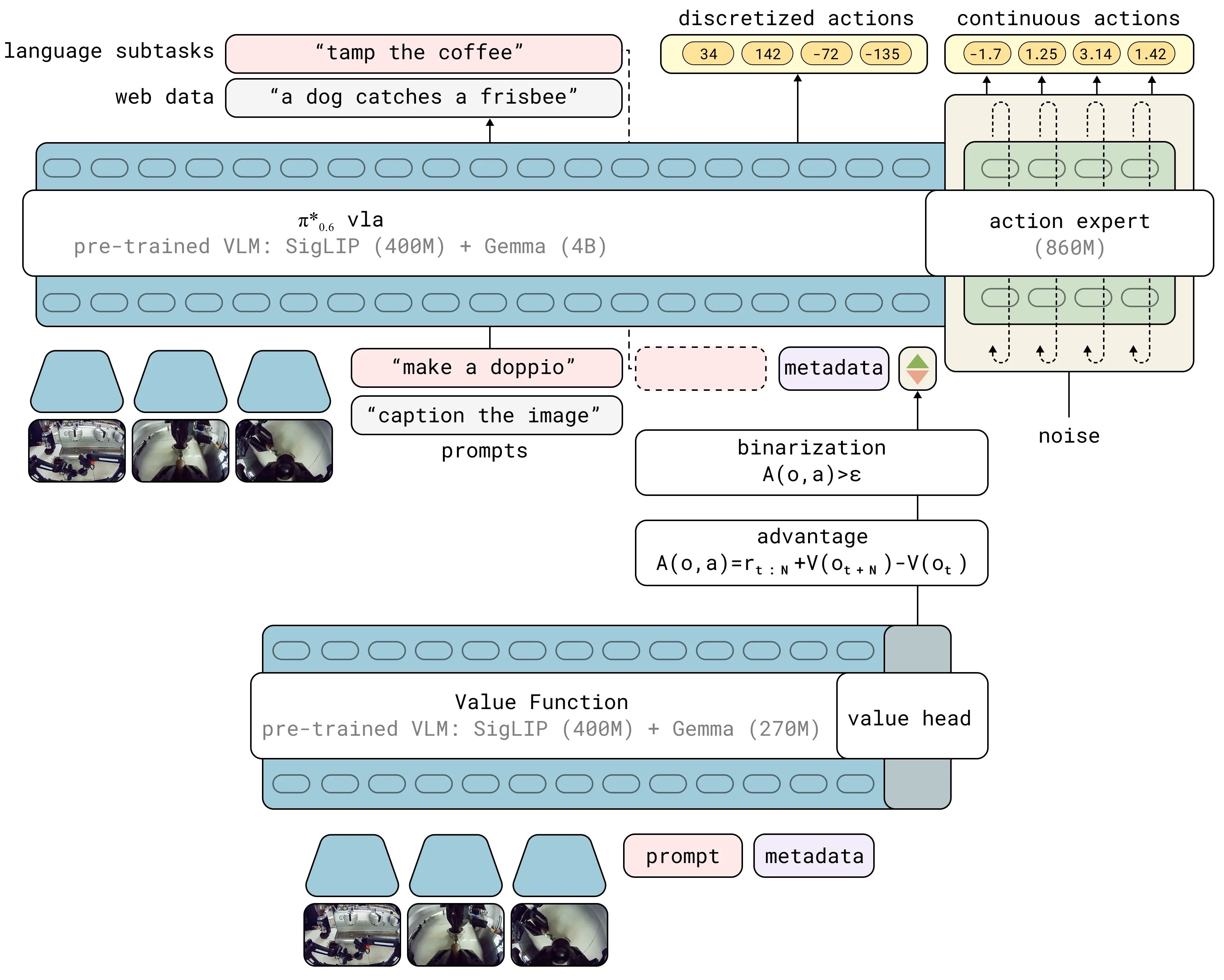
- 提出的 **π*₀.₆ 模型通过 RECAP** 框架进行预训练和在线微调,能够处理折叠衣物、组装纸箱、制作意式咖啡等复杂、精细的现实世界任务。
Card 01
研究单位
研究单位
- Physical Intelligence
Card 02
论文概述
论文概述
- 论文研究了视觉-语言-行动(VLA)模型如何通过真实世界部署中的强化学习(RL)进行自我改进,提出了一个名为 RECAP 的通用方法框架。
- 核心目标是解决VLA模型超越模仿学习、利用自主实践经验进行“练习”以掌握技能、提升鲁棒性和执行速度的问题。
- 提出的 **π*₀.₆ 模型通过 RECAP** 框架进行预训练和在线微调,能够处理折叠衣物、组装纸箱、制作意式咖啡等复杂、精细的现实世界任务。
Card 03
核心贡献
核心贡献
- 提出了 RECAP 框架,一个将演示数据、自主经验与专家干预整合到强化学习训练管线中的通用方法,通过优势条件策略提取实现VLA模型的自我改进。
- 发布了 **π*₀.₆ 模型,这是基于 π₀.₆** 模型改进并支持优势条件输入的VLA模型,能够从价值函数中提取改进策略。
- 在极具挑战性的现实世界任务(如折叠多种衣物、组装纸箱、制作意式咖啡)上验证了方法的有效性,展示了通过自主经验学习显著提升任务吞吐量和成功率的潜力。
- 提出了一种可扩展的优势条件策略提取方法,避免了传统策略梯度方法在大型流匹配VLA模型上应用的复杂性,能够有效利用异构的离线数据。
Card 04
方法描述
方法描述
- RECAP 方法包含三个核心步骤循环:1) 在机器人上运行策略收集数据并获得奖励标签及可选的专家干预;2) 使用所有数据训练一个多任务分布式价值函数;3) 基于价值函数估计的优势值,通过优势条件训练来提取改进策略。
- 核心技术是 优势条件策略提取。策略被训练为能够以一个二元化的“优势指示器”(I)作为额外输入。在推理时,固定I=True可直接采样到改进的策略,无需显式的策略梯度优化。
- 价值函数训练采用分布式值函数形式,将观测和语言指令映射到离散化的价值分布,通过交叉熵损失进行训练,能够判断任务失败和预测完成所需时间。
Card 05
数据集与资源
数据集与资源
- 预训练数据集:包含来自多种机器人平台和任务、总计数万小时的多样化演示数据,并结合了网络视觉-语言数据。
- 模型规模:**π*₀.₆ VLA模型使用 Gemma 3 4B 作为骨干网络,包含一个 860M参数 的专用动作专家。价值函数使用一个较小的 670M参数** VLM骨干。
- 训练资源:论文未明确说明具体的计算资源(如GPU/TPU数量),但提到了大规模预训练和多机器人数据平台的使用。
Card 06
评估与结果
评估与结果
- 评估环境与基准:在真实世界的双臂机器人平台上进行评估,任务包括:标准洗衣折叠、多样化衣物折叠、结构化衬衫折叠、双份浓缩咖啡制作、纸箱组装。
- 主要评估指标:任务成功率(Success Rate)和任务吞吐量(每小时成功完成的任务数)。
- 关键实验结果:
- 在最具挑战性的任务(多样化衣物折叠、咖啡制作)上,应用 RECAP 后,任务吞吐量提升超过 2倍。
- 任务失败率显著降低,部分任务降低 2倍 以上。
- 方法能够通过少量数据和在线迭代,有效移除策略中的特定失败模式(如衣物折叠中领口朝下的错误)。
- 相比于PPO等基于策略梯度的方法,本文提出的优势条件方法在相同数据下取得了更好的性能。