一眼看懂
封面预览
提出了 NORA-1.5,一种基于预训练 NORA 模型构建的视觉-语言-动作(VLA)模型,通过集成流匹配(flow-matching)ba…
- 提出了 NORA-1.5,一种基于预训练 NORA 模型构建的视觉-语言-动作(VLA)模型,通过集成流匹配(flow-matching)ba…
- 解决了现有 VLA 模型在可靠性、泛化能力以及跨不同实施方式和真实环境部署方面的不足
- 开发了一套基于世界模型(World Model)和动作的偏好奖励机制,用于 VLA 策略的后训练(post-training),通过直接偏好优…
Card 01
研究单位
研究单位
- 南洋理工大学 (Nanyang Technological University, NTU) - 作者:Chia-Yu Hung, Navonil Majumder, Haoyuan Deng, Liu Renhang, Yankang Ang, Ziwei Wang, Soujanya Poria
- Lambda Labs - 作者:Amir Zadeh, Chuan Li
- 新加坡科技设计大学 (Singapore University of Technology and Design, SUTD) - 作者:Dorien Herremans
Card 02
论文概述
论文概述
- 提出了 NORA-1.5,一种基于预训练 NORA 模型构建的视觉-语言-动作(VLA)模型,通过集成流匹配(flow-matching)based 动作专家来提升性能
- 解决了现有 VLA 模型在可靠性、泛化能力以及跨不同实施方式和真实环境部署方面的不足
- 开发了一套基于世界模型(World Model)和动作的偏好奖励机制,用于 VLA 策略的后训练(post-training),通过直接偏好优化(DPO)来提升模型鲁棒性和任务成功率
Card 03
核心贡献
核心贡献
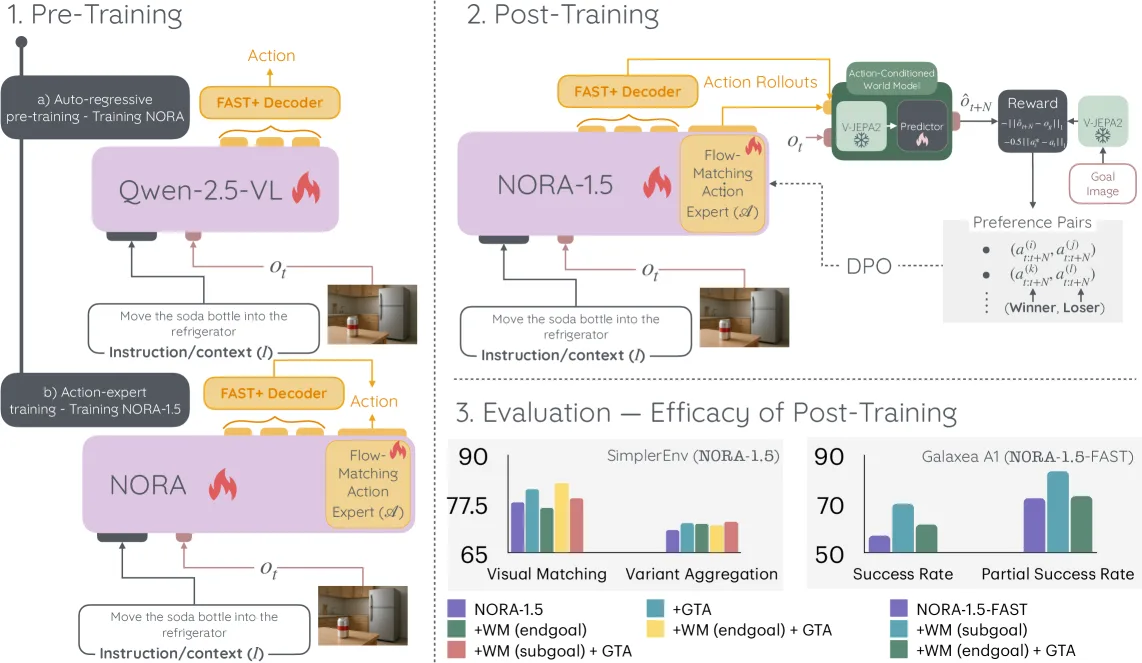
- 引入 NORA-1.5:在预训练自回归 VLA 模型(NORA)基础上集成流匹配动作专家,在 SimplerEnv 和 LIBERO 模拟基准测试中取得最先进性能,并能迁移到真实机器人(Galaxea A1)
- 多策略动作奖励机制:提出(i)基于世界模型的目标奖励(V-JEPA2-AC)、(ii)基于真实动作的距离奖励(GTA)、(iii)子目标评分等互补信号,为 VLA 动作排序提供鲁棒且可扩展的标准
- 全面架构分析:详细研究流匹配专家与自回归 VLA 主干耦合的效果,发现两者存在强协同效益
- 推进 VLA 可扩展后训练:证明简单奖励模型结合 DPO 偏好优化在模拟和真实机器人环境中均能带来一致的性能提升
Card 04
方法描述
方法描述
- 模型架构:使用 NORA(基于 Qwen-2.5-VL-3B,3B 参数)作为 VLA 主干,通过分层自注意力耦合流匹配动作专家 A,直接回归动作序列 a_{t:t+N}(N=5)
- 流匹配动作专家:参数化为堆叠 Transformer 网络,使用流匹配损失函数训练,将噪声动作序列映射到真实动作速度
- 奖励模型设计:
- WM 目标奖励(公式6):使用 V-JEPA2-AC(1.3B 参数)预测动作执行后的未来帧嵌入,与目标帧嵌入比较
- GTA 动作奖励(公式7):测量采样动作与真实动作的 L1 距离
- 总奖励(公式8):两者加权组合(R_g + 0.5R_a)
- 偏好数据集构建:从 VLA 采样 N 个动作序列,使用奖励函数排序,构建 (winner, loser) 偏好对
- DPO 后训练:使用 DPO 目标(公式9)对动作专家进行偏好优化,同时对齐 FAST+ 动作输出
Card 05
数据集与资源
数据集与资源
- 预训练数据:Open X-Embodiment 数据集
- 模拟基准:SimplerEnv(4M 帧)、LIBERO(500 episodes × 4 subsets)
- 真实机器人数据:Galaxea A1 机械臂(1,000 条遥操作演示,9 个任务)
- 世界模型:V-JEPA2-AC(1.3B 参数)
- VLA 主干:NORA(3B 参数,基于 Qwen-2.5-VL-3B)
- 动作分词器:FAST+ tokenizer
Card 06
评估与结果
评估与结果
- SimplerEnv 基准:
- NORA-1.5 (fine-tuned) 达到 77.9% 平均成功率(Visual Matching)和 70.7%(Variant Aggregation)
- NORA-1.5 (DPO) 进一步提升至 82.8%(Visual Matching),比 SFT 基线提高 4.9%
- LIBERO 基准:
- NORA-1.5 达到 94.5% 平均成功率,超越 π₀ 等先进模型
- NORA-1.5 (DPO) 达到 95.0%,尤其在 Long 子集提升至 90.5%
- 真实机器人(Galaxea A1):
- NORA-1.5 平均成功率达到 71.11%,比 π₀(25.55%)和 NORA(58.88%)分别提升 46% 和 13%
- 在含干扰物的未见任务中表现尤为突出,显示强鲁棒性
- DPO 影响:WM(subgoal)+ GTA 组合在 SimplerEnv 上获最佳综合表现(82.8%),验证混合奖励策略有效性