一眼看懂
封面预览
论文旨在解决端到端自动驾驶系统在长尾、未知场景下泛化能力不足的核心问题。
- 论文旨在解决端到端自动驾驶系统在长尾、未知场景下泛化能力不足的核心问题。
- 针对现有结合视觉语言模型(VLM)的方案(如双系统框架、VLA模型)存在的系统不一致或计算成本过高的问题,提出了一个高效的解决方案。
- 核心目标是利用VLM的风险感知推理能力,通过知识蒸馏增强紧凑的端到端驾驶模型的BEV特征表示,从而提升其在复杂场景下的感知与规划性能。
Card 01
研究单位
研究单位
- 清华大学
- 华为技术有限公司(2012 Laboratories)
Card 02
论文概述
论文概述
- 论文旨在解决端到端自动驾驶系统在长尾、未知场景下泛化能力不足的核心问题。
- 针对现有结合视觉语言模型(VLM)的方案(如双系统框架、VLA模型)存在的系统不一致或计算成本过高的问题,提出了一个高效的解决方案。
- 核心目标是利用VLM的风险感知推理能力,通过知识蒸馏增强紧凑的端到端驾驶模型的BEV特征表示,从而提升其在复杂场景下的感知与规划性能。
Card 03
核心贡献
核心贡献
- 提出了一个专门用于自动驾驶场景的VLM风险检测管道,实现了无需模型微调的零样本风险对象识别与评分能力。
- 开发了一种专门的蒸馏架构,能够有效地将大型VLM的风险感知知识迁移到紧凑的端到端驾驶模型中,同时保持计算效率。
- 提出了RiskHead插件模块,通过BEV特征反向投影和可变形注意力机制,实现了风险语义在BEV空间中的有效蒸馏。
- 实验证明,该方法在感知精度、规划稳定性和闭环测试得分上均取得了显著提升,特别是在长尾场景中表现优异。
Card 04
方法描述
方法描述
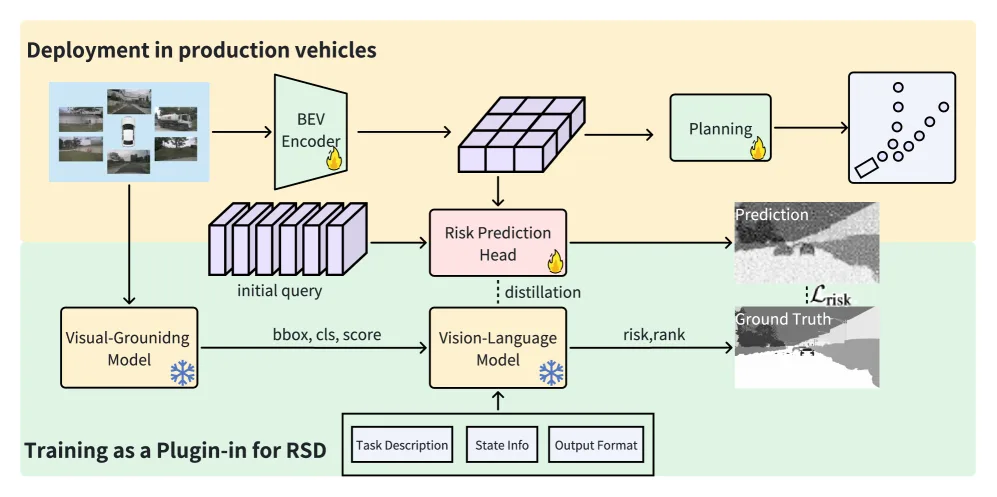
- 提出Risk Semantic Distillation框架,整体流程分为VLM增强的风险语义标注和风险语义蒸馏两个阶段。
- 在标注阶段,利用 OV-DINO 模型进行开放词汇的视觉定位,生成对象边界框和类别;然后结合 Qwen-2.5 等VLM模型,通过精心设计的提示和风险链式思维进行推理,输出风险对象评分。
- 在蒸馏阶段,引入RiskHead模块处理BEV特征。关键技术包括:
- BEV Rebatching Procedure:为提高内存和推理效率,仅处理每个相机视野内的BEV查询。
- Nearest Neighbor Matching:将BEV特征对应的3D参考点投影到2D视角,并通过最近邻匹配与图像上的风险语义区域对齐。
- Deformable Attention:以对齐后的2D点为参考,通过可变形注意力从多视角图像特征中聚合信息,生成风险预测。
- 将风险预测损失(L1范数)集成到端到端模型(基于VAD架构)的总损失函数中,实现端到端训练。
Card 05
数据集与资源
数据集与资源
- 使用 Bench2Drive 数据集进行训练和评估,该数据集包含44种长尾驾驶场景(如Cutin, Construction, Accident等)。
- 模型骨干网络采用 ResNet-50,并使用FPN进行多尺度特征聚合。
- BEV特征图分辨率为 100x100。
- 训练使用AdamW优化器,学习率为2e-4,并采用余弦退火学习率调度。
- 蒸馏模型总参数量约50M,推理效率比典型的VLM-AD架构提升10倍以上。
Card 06
评估与结果
评估与结果
- 在 Bench2Drive 基准上进行评估,对比基线为 VAD 模型。
- 感知指标:VAD-RSD 在mAP上提升至0.5195,mASE从0.0854降至0.0544,NDS提升至0.6280,显示出显著的空间感知精度提升。
- 规划指标:VAD-RSD 在ADE(1s/2s)和碰撞率(Col_1s/2s/3s)上均显著低于基线,表明轨迹预测更准确、更安全。
- 闭环测试:在仅使用10%训练数据的设置下,VAD-Tiny-RSD 的Driving Score从36.306提升至46.662,Success Rate从0.167提升至0.278。
- 定性分析表明,RiskHead能够有效重建并高亮显示场景中的关键风险对象(如穿越车辆、被遮挡车辆),验证了其良好的可解释性。