一眼看懂
封面预览
论文提出了一个名为 CCoL 的新型行为克隆框架,旨在解决语言条件操作中的复合误差问题。
- 论文提出了一个名为 CCoL 的新型行为克隆框架,旨在解决语言条件操作中的复合误差问题。
- 研究针对现有方法中存在的物理不连续性和语义-物理错位问题,确保时序一致的执行和细粒度的语义基础。
- 该框架通过视觉、语言和本体感知输入的连续协同学习,生成鲁棒且平滑的动作执行轨迹。
Card 01
研究单位
研究单位
- The Hong Kong Polytechnic University(香港理工大学)
- The Education University of Hong Kong(香港教育大学)
Card 02
论文概述
论文概述
- 论文提出了一个名为 CCoL 的新型行为克隆框架,旨在解决语言条件操作中的复合误差问题。
- 研究针对现有方法中存在的物理不连续性和语义-物理错位问题,确保时序一致的执行和细粒度的语义基础。
- 该框架通过视觉、语言和本体感知输入的连续协同学习,生成鲁棒且平滑的动作执行轨迹。
Card 03
核心贡献
核心贡献
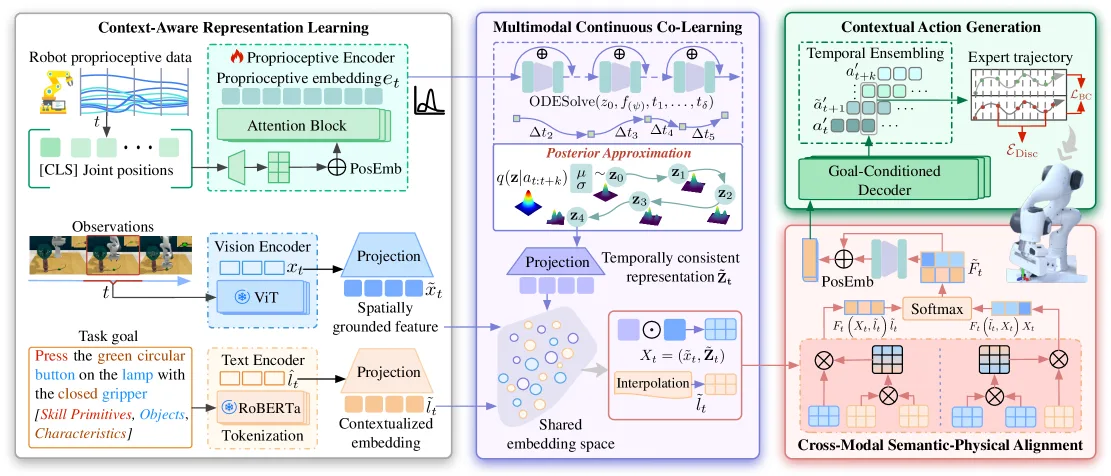
- 提出了多模态连续协同学习(MCC)机制,利用 NeuralODEs 在潜在空间中建模时间依赖性,确保平滑的动作状态转换。
- 引入了跨模态语义-物理对齐(CSA)模块,通过双向交叉注意力机制将语言规范逐步锚定到视觉运动表征中。
- 在三个模拟套件中取得了最先进的性能,并在真实机器人上验证了其有效性,平均相对提升 8.0%。
Card 04
方法描述
方法描述
- 采用 ViT 作为视觉编码器,RoBERTa 作为文本编码器,以及 CVAE 作为本体感知编码器。
- 利用 Neural Ordinary Differential Equations (NeuralODEs) 建模本体感知嵌入的连续演变,构建共享潜在空间以捕获时间连贯性。
- 设计了双向交叉注意力机制,将语言语义(如动词、名词)与视觉区域和机器人状态对齐,实现逐步的语义适应。
- 使用目标条件解码器生成动作序列,并通过混合损失函数(包含重建损失、KL散度和不连续性惩罚)进行优化。
Card 05
数据集与资源
数据集与资源
- 使用了 Aloha MuJoCo、RLBench 和 Franka Kitchen 三个模拟环境数据集。
- 真实世界实验使用了 7-DoF Franka Emika Panda 机器人和 Intel RealSense D435i RGB-D 相机。
- 模型基于 ViT-S/B 和 RoBERTa,在 RTX 4090 GPU 上进行训练,单任务训练时长约 5.3 小时。
Card 06
评估与结果
评估与结果
- 在 Aloha MuJoCo 双臂任务中,CCoL 平均成功率显著优于 ACT 和 AWE,在人类演示的双臂插入任务中相比 DIC 提升了 19.2%。
- 在 RLBench 中,CCoL_3D 在 3D 设置下平均成功率达到 84.9%,超越了 3DDiff。
- 在 Franka Kitchen 长视野任务中,使用 ViT-B 骨干网络取得了 38.1% 的平均成功率。
- 真实世界实验表明,CCoL 在未见过的物体状态下保持高成功率(如立方体放置任务 86.7%),并且显著减少了轨迹的速度和加速度波动。