一眼看懂
封面预览
研究机器人操作中,在涉及视觉相似对象的序列交互等非马尔可夫场景下,智能体需要感知、跟踪和推理个体对象实例随时间变化的能力。
- 研究机器人操作中,在涉及视觉相似对象的序列交互等非马尔可夫场景下,智能体需要感知、跟踪和推理个体对象实例随时间变化的能力。
- 指出当前视觉-语言-动作模型通常仅依赖最新观测,缺乏编码和回忆以对象为中心的历史记录的机制,在部分可观测环境中易失败。
- 提出一个新的非马尔可夫操作任务套件 LIBERO-Mem 用于压力测试,并设计一个基于槽位状态空间建模的可扩展VLA框架 Embodied-S…
Card 01
研究单位
研究单位
- 论文作者来自多个机构(具体单位信息在提供的HTML片段中未完整显示)。
Card 02
论文概述
论文概述
- 研究机器人操作中,在涉及视觉相似对象的序列交互等非马尔可夫场景下,智能体需要感知、跟踪和推理个体对象实例随时间变化的能力。
- 指出当前视觉-语言-动作模型通常仅依赖最新观测,缺乏编码和回忆以对象为中心的历史记录的机制,在部分可观测环境中易失败。
- 提出一个新的非马尔可夫操作任务套件 LIBERO-Mem 用于压力测试,并设计一个基于槽位状态空间建模的可扩展VLA框架 Embodied-SlotSSM 来维持结构化、以对象为中心的记忆。
Card 03
核心贡献
核心贡献
- 提出 LIBERO-Mem,一个新颖的非马尔可夫机器人操作基准,系统性地在长程任务上评估记忆增强模型,强调对象持久性、历史推理和结构化记忆保持。
- 提出 Embodied-SlotSSM,一个基于槽位的状态空间建模框架,编码持久、以对象为中心的记忆表示,支持在部分可观测下的结构化跟踪和决策。
- 通过在一般马尔可夫和特殊非马尔可夫设置下的实验,证明所提方法能增强有状态推理、长程动作预测和操作任务性能。
Card 04
方法描述
方法描述
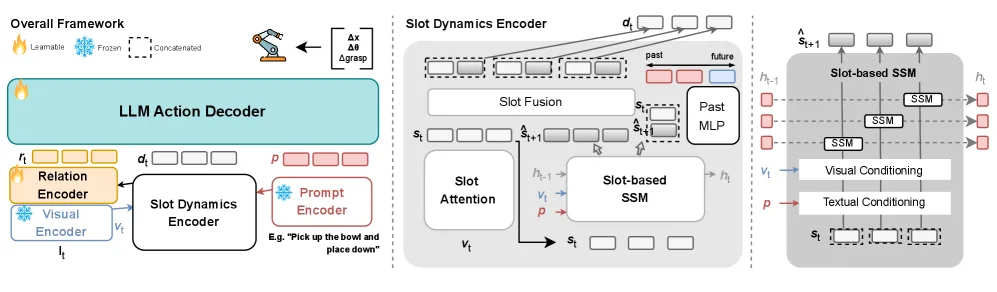
- 提出一种以对象为中心的视觉-语言-动作框架,核心是结合槽位注意力机制与状态空间模型来建模时间序列。
- 使用 Slot Attention 将密集视觉嵌入分解为一组模块化的、以对象为中心的标记,实现场景解耦和对象定位。
- 引入 SlotSSM 模块,通过输入依赖的递归更新来维护每个对象槽位的隐藏状态,从而建模其短期历史和动态,形成瞬态记忆。
- 采用时间对比损失来增强槽位表示在时间上的身份一致性,实现跨时间步的对象跟踪。
- 设计一个关系编码器,通过交叉注意力融合槽位动态信息与原始视觉特征,生成关系标记用于上下文感知推理。
- 最终动作通过一个槽位条件解码器预测,该解码器以关系标记、槽位动态和任务指令为条件,实现时间上接地、上下文感知的动作预测。
Card 05
数据集与资源
数据集与资源
- 使用了 LIBERO-Goal 基准进行通用任务性能评估。
- 提出并使用了新的 LIBERO-Mem 基准,包含10个任务,涵盖四种记忆维度:对象运动(OM)、对象序列(OS)、对象关系(OR)、对象遮挡(OO)。
- LIBERO-Mem 每个任务包含120条轨迹(100条训练,20条验证),每条轨迹200-700帧。
- 模型默认使用 16个槽位 进行对象级表示。
Card 06
评估与结果
评估与结果
- 在 LIBERO-Goal 基准上,提出的 Naive E-SlotSSM 平均成功率达到 83.0%,超越了SlotVLA (h=8) 的 75.5%。
- 在 LIBERO-Mem 基准上,Naive E-SlotSSM 实现了 14.8% 的平均子目标完成率,显著优于其他基线模型(最高为5.0%)。
- 可视化分析表明,模型能够随时间持续关注目标对象,显示出鲁棒的对象持久性和跟踪能力。
- 实验揭示了在非马尔可夫设置下,细粒度子目标跟踪的困难性,以及基于槽位的时序记忆提供的强归纳偏置的优势。