一眼看懂
封面预览
研究旨在解决视觉语言动作(Vision-Language-Action, VLA)模型在多机器人协作场景中的适应性问题
- 研究旨在解决视觉语言动作(Vision-Language-Action, VLA)模型在多机器人协作场景中的适应性问题
- 当前先进的自回归 VLA 模型(如 OpenVLA)在单臂操作任务表现出色,但在多机器人系统中性能显著下降
- 提出 ET-VLA 框架,包含两个核心技术:合成持续预训练(Synthetic Continued Pretraining, SCP)和具身思…
Card 01
研究单位
研究单位
- 上海大学 (Shanghai University) - Chengmeng Li, Yaxin Peng
Card 02
论文概述
论文概述
- 研究旨在解决视觉语言动作(Vision-Language-Action, VLA)模型在多机器人协作场景中的适应性问题
- 当前先进的自回归 VLA 模型(如 OpenVLA)在单臂操作任务表现出色,但在多机器人系统中性能显著下降
- 提出 ET-VLA 框架,包含两个核心技术:合成持续预训练(Synthetic Continued Pretraining, SCP)和具身思维图(Embodied Graph-of-Thought, EGoT)
Card 03
核心贡献
核心贡献
- 深入分析现有自回归 VLA 模型在多机器人多任务场景中的失败模式
- 提出 ET-VLA 框架,通过 SCP 和 EGoT 显著提升 VLA 在多机器人操作任务中的性能
- 在真实机器人和仿真环境中广泛评估,ET-VLA 在六项真实任务中成功率比 OpenVLA 高出 53.2%
- 首个成功实现将预训练 VLA 有效迁移到双臂机器人系统的方法
Card 04
方法描述
方法描述
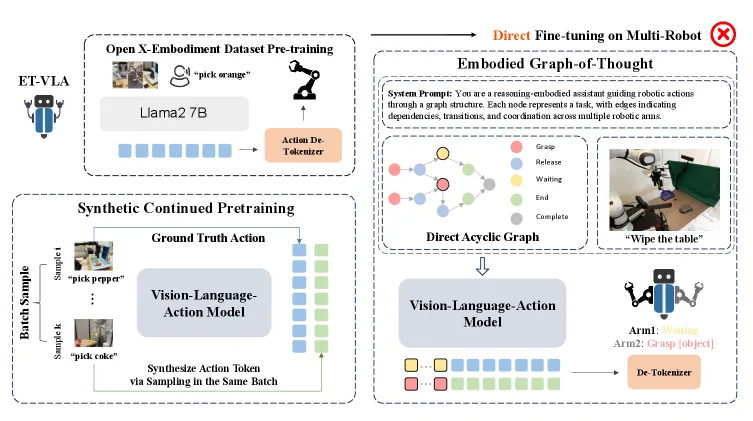
- 问题根源:现有 VLA 预训练数据(如 Open X-Embodiment)仅包含单臂机器人数据,导致模型无法生成控制多机器人所需的足够 action tokens
- 合成持续预训练(SCP):通过跨采样策略生成合成多机器人数据,使模型学习生成 14 个 action tokens(每个机器人 7 个 DoF),无需真实人类演示数据
- 具身思维图(EGoT):将复杂任务分解为动作图结构,明确表示任务间的时序依赖关系,帮助模型理解不同机器人的功能和角色,促进有效协作
- 技术流程:首先进行 SCP 预训练,然后针对目标 embodiment 进行微调
Card 05
数据集与资源
数据集与资源
- 真实机器人数据集:458 条轨迹(6 项任务)+ 980 条额外人类演示轨迹
- 双臂机器人:bimanual UR5e, bimanual Franka, bimanual AgileX
- 仿真基准:RLBench2(13 项双臂任务),RoboTwin(14 项任务)
- 训练资源:16 块 A100 GPU,SCP 阶段学习率 2e-5 训练 1 epoch,微调阶段学习率 2e-4 训练 20 epochs
Card 06
评估与结果
评估与结果
- 真实机器人实验:ET-VLA 平均成功率达 59.74%,远超 OpenVLA 的 6.49%
- RLBench2 仿真:ET-VLA 达到 10.2% 成功率,显著优于 ACT(5.9%)和 OpenVLA(1.2%)
- RoboTwin 仿真:ET-VLA 达到 40.1%,优于 Diffusion Policy 的 27.7%
- 消融实验:移除 SCP 后性能降至 37.66%,移除 SCP 和 EGoT 后仅剩 6.49%,证明两个组件均为关键贡献