一眼看懂
封面预览
提出Unified Diffusion VLA (UD-VLA),一种通过联合离散去噪扩散过程(JD3P)统一视觉-语言-动作建模的机器人智能…
- 提出Unified Diffusion VLA (UD-VLA),一种通过联合离散去噪扩散过程(JD3P)统一视觉-语言-动作建模的机器人智能…
- 解决现有统一VLA模型中图像生成与动作预测分离、缺乏内在协同的问题,实现理解、生成与执行的深度耦合
- 核心创新:通过同步去噪轨迹联合优化视觉生成和动作预测,使动作在充分的视觉引导下迭代精化
Card 01
研究单位
研究单位
- HKUST(GZ)(香港科技大学广州校区):Jiayi Chen, Wenxuan Song, Ziyang Zhou, Haoang Li
- Westlake University(西湖大学):Pengxiang Ding, Han Zhao, Donglin Wang
- Zhejiang University(浙江大学):Pengxiang Ding, Han Zhao
- Monash University(莫纳什大学):Feilong Tang
Card 02
论文概述
论文概述
- 提出Unified Diffusion VLA (UD-VLA),一种通过联合离散去噪扩散过程(JD3P)统一视觉-语言-动作建模的机器人智能体模型
- 解决现有统一VLA模型中图像生成与动作预测分离、缺乏内在协同的问题,实现理解、生成与执行的深度耦合
- 核心创新:通过同步去噪轨迹联合优化视觉生成和动作预测,使动作在充分的视觉引导下迭代精化
Card 03
核心贡献
核心贡献
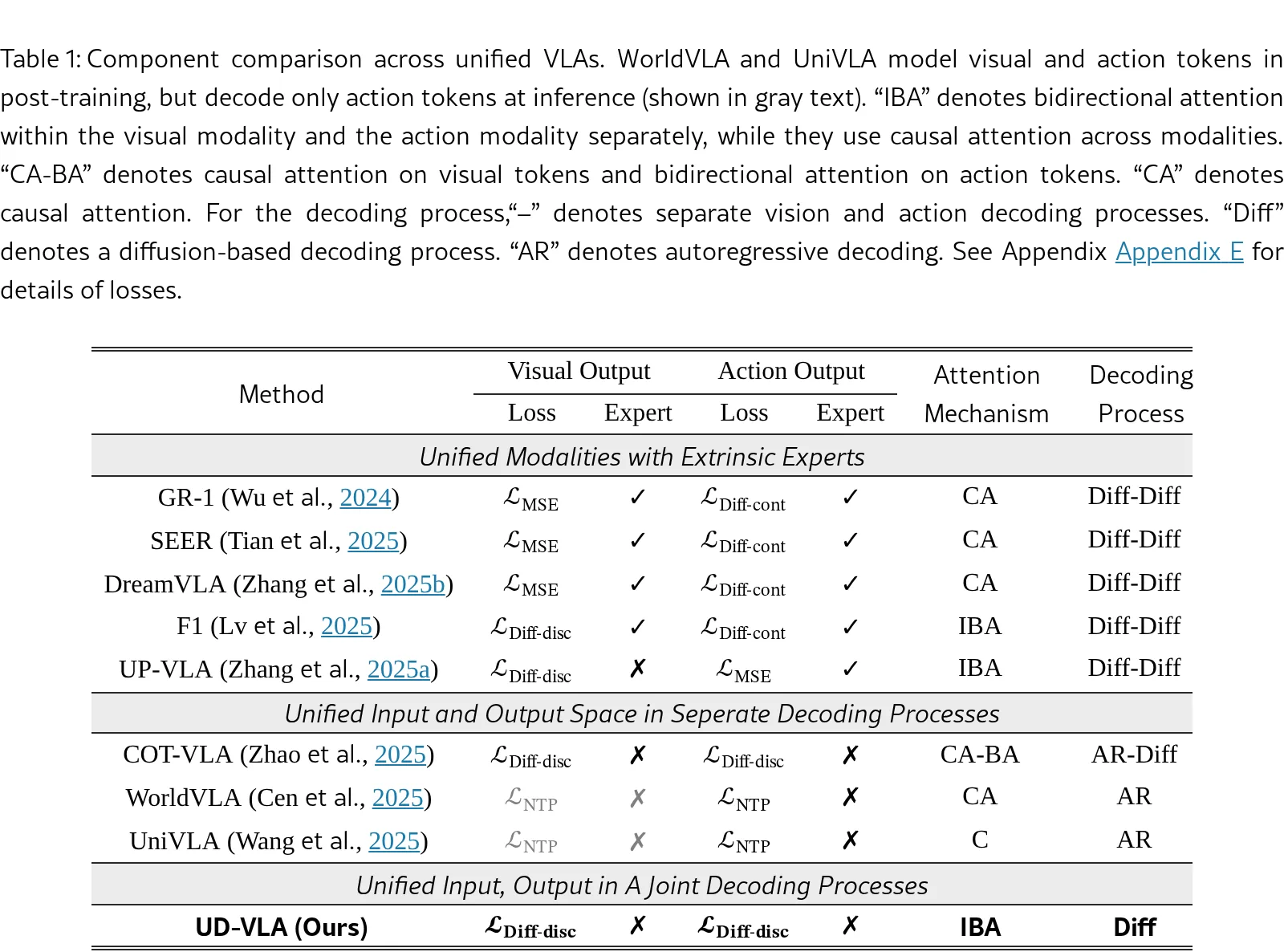
- 提出Unified Diffusion VLA架构,首次实现理解、生成、执行三者的紧密耦合与相互增强
- 设计Joint Discrete Denoising Diffusion Process (JD3P),将多模态信息整合到单一去噪轨迹中,作为跨模态协同的核心机制
- 构建混合注意力机制(Hybrid Attention),在保持模态内双向交互的同时强制跨模态因果注意力,避免信息泄露
- 开发两阶段训练流程:先扩展VLM的图像预测能力,再联合训练图像生成与动作预测
- 引入推理优化技术:KV缓存、预填充token、置信度引导解码、解码空间映射,实现4倍于自回归方法的推理速度
Card 04
方法描述
方法描述
- 统一离散化空间:使用VQ分词器处理图像,FAST分词器处理动作,将语言、视觉、动作统一为离散token序列
- JD3P扩散过程:定义联合马尔可夫链,以概率β_t将token掩码为特殊token M,通过单步mask-predict目标优化
- 混合注意力设计:输入文本与当前图像分别采用因果/双向注意力;输出分为图像生成块(双向)和动作块(双向),块间采用因果注意力(动作→图像)
- 推理加速策略:前缀KV缓存、预填充特殊token、基于置信度的TopK选择、温度退火的Gumbel采样、模态特定的解码空间限制
Card 05
数据集与资源
数据集与资源
- 预训练数据:大规模视频数据集(用于第一阶段图像生成能力注入)
- 机器人动作数据集:CALVIN、LIBERO、SimplerEnv等基准的机器人操作数据
- 模型基础:基于预训练VLM(Emu3风格)扩展,使用VQ视觉分词器和FAST动作分词器
- 训练硬件:具体GPU/TPU配置未在提供的HTML片段中明确说明
Card 06
评估与结果
评估与结果
- CALVIN基准:在ABCD→D任务上达到平均成功长度4.64,超越所有基线(如MDT 4.52、UP-VLA 4.42、UniVLA* 4.26)
- LIBERO基准:平均成功率92.7%,达到SOTA;Long套件89.6%(最高),Object套件95.7%
- SimplerEnv-WidowX:平均成功率62.5%,显著超越F1(59.4%)、π₀-FAST(48.3%)、SpatialVLA(42.7%)等方法
- 真实世界实验:在UR5e机械臂+Inspire灵巧手上的堆叠、放置、翻转任务中,成功率超80%,泛化能力优于GR00T N1和UniVLA
- 推理速度:219.3 tokens/s,相比自回归方法(50.2 tokens/s)实现4.3倍加速