一眼看懂
封面预览
当前 Vision-Language-Action (VLA) 模型受限于僵化的静态交互范式,缺乏同时感知、倾听、说话和执行动作的能力,也无法…
- 当前 Vision-Language-Action (VLA) 模型受限于僵化的静态交互范式,缺乏同时感知、倾听、说话和执行动作的能力,也无法…
- 论文提出 VITA-E,一种新型人机交互框架,实现行为并发和近实时中断,使机器人能够像人类一样进行多任务处理
- 双模型架构实现并发交互:两个并行VLA实例分别作为"主动模型"和"待机模型",支持行为并发和即时任务中断
Card 01
研究单位
研究单位
- Nanjing University (Xiaoyu Liu, Chu Wu, Shaoqi Dong, Caifeng Shan)
- Tencent Youtu Lab (Chaoyou Fu, Chi Yan, Haihan Gao, Yunhang Shen, Deqiang Jiang, Haoyu Cao, Xing Sun)
- CASIA (Yi-Fan Zhang, Ran He)
- Fourier Intelligence Inc. (Cheng Qian, Bin Luo, Xiuyong Yang, Guanwu Li, Yusheng Cai)
Card 02
论文概述
论文概述
- 当前 Vision-Language-Action (VLA) 模型受限于僵化的静态交互范式,缺乏同时感知、倾听、说话和执行动作的能力,也无法处理实时用户中断
- 论文提出 VITA-E,一种新型人机交互框架,实现行为并发和近实时中断,使机器人能够像人类一样进行多任务处理
Card 03
核心贡献
核心贡献
- 双模型架构实现并发交互:两个并行VLA实例分别作为"主动模型"和"待机模型",支持行为并发和即时任务中断
- 特殊令牌控制流:设计 [ACT]、[HALT]、[RES]、[INST]、[END] 等特殊令牌,由VLM生成以直接驱动系统状态转换,实现"模型即控制器"范式
- 交互式VLA训练方法:提出数据策划和微调策略,教授VLM生成系统级控制令牌,兼容主流VLM+Diffusion Action Expert架构
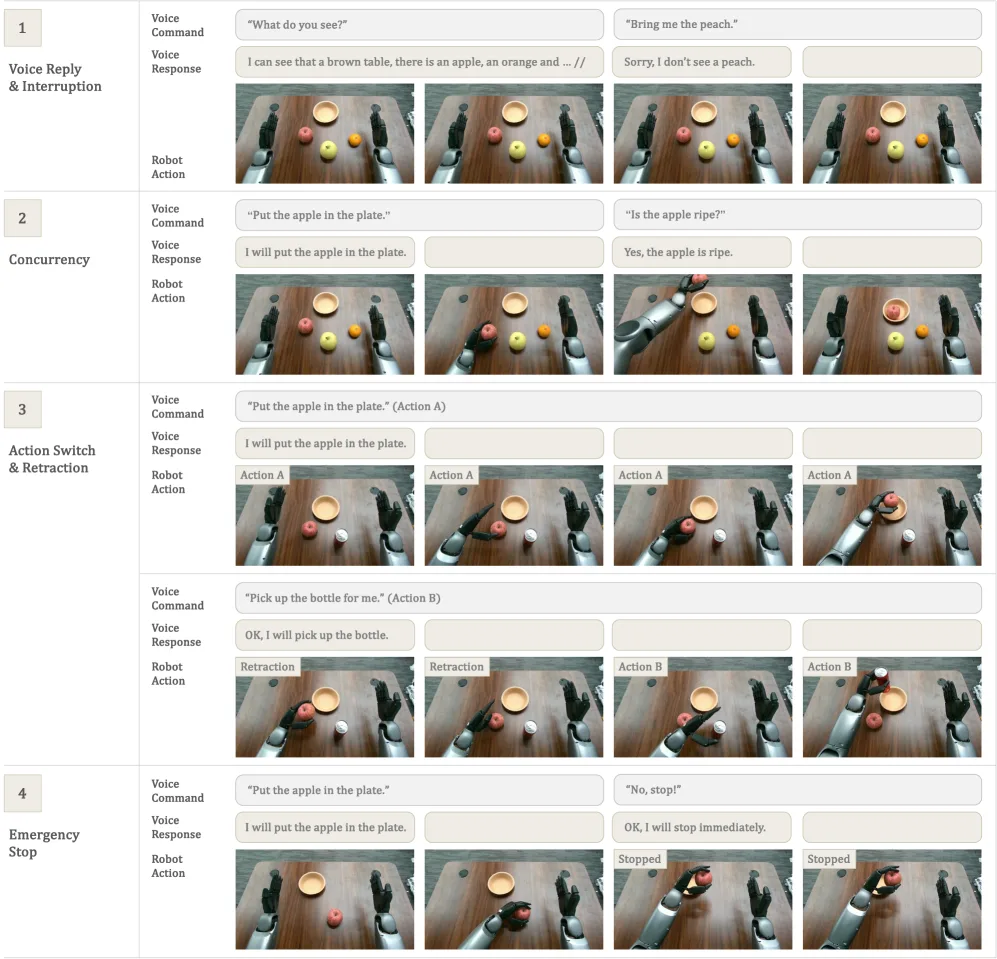
- 动态交互能力:支持四种主要交互模式——并发执行、语音中断、动作切换和紧急停止
Card 04
方法描述
方法描述
- 采用双系统架构:VITA-1.5 作为VLM(System-2)负责高级理解,Diffusion Transformer 作为动作专家(System-1)负责低级运动控制
- 模型即控制器范式:通过微调VLM生成特殊控制令牌,将模型推理与系统行为紧密耦合
- 数据策划策略:基于 ActionNet、Libero 和自收集真实场景数据,通过自动化标注流程插入特殊令牌
- 双模型协调机制:使用同步原语(如信号量)控制模型状态切换,待机模型可抢占主动模型处理中断
Card 05
数据集与资源
数据集与资源
- Libero 基准测试(Spatial、Object、Goal、LONG四个任务套件)
- Libero-90 预训练数据集,Libero-10 微调数据
- 真实机器人数据:每个任务300次演示,20Hz采集,26自由度
- Fourier GR2 人形机器人平台,配备 Realsense D455 RGB相机
- 训练配置:batch size 64,学习率 1e-4,AdamW优化器,cosine衰减,20,000步训练
Card 06
评估与结果
评估与结果
- 仿真环境:Libero基准,与 GR00T 对比,成功率略低于端到端训练基线(因VLM冻结)
- 真实机器人任务:"拿起罐子"和"拿起玩具放入篮子",30次试验,与 π₀、Diffusion Policy、GR00T、SmolVLA 对比,性能达到SOTA水平
- 交互任务评估:
- 语音中断成功率:100%
- 紧急停止成功率:100%
- 任务切换成功率:93.3%
- 平均语音响应延迟:2.26秒
- 消融研究:微调后的VITA-E VLM在生成动作指令(95% vs 10%)和紧急停止(100% vs 0%)方面显著优于基础VITA-1.5模型