一眼看懂
封面预览
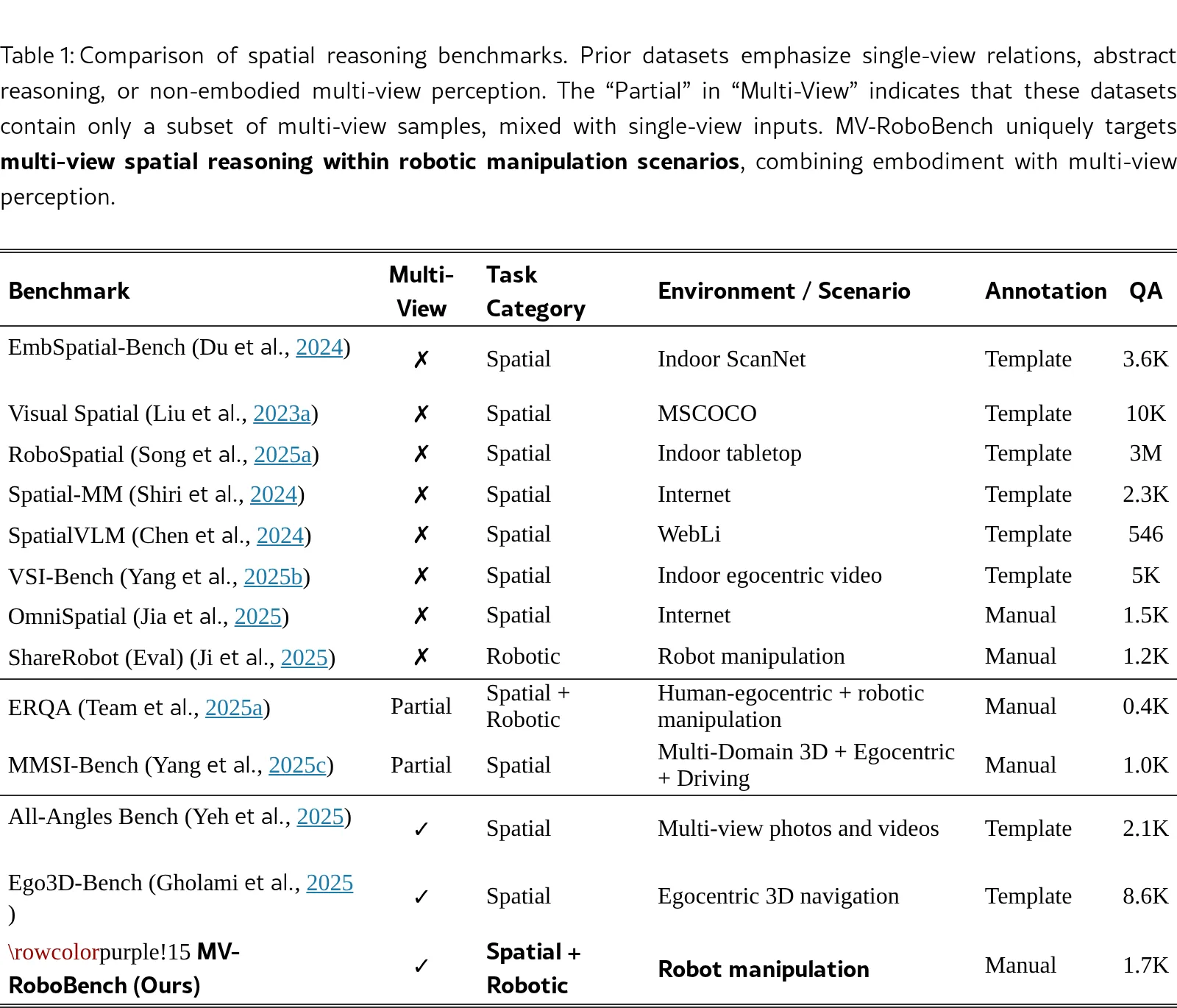
论文提出了 MV-RoboBench,这是首个专门评估视觉语言模型(VLMs)在机器人操作场景中多视角空间推理能力的基准测试
- 论文提出了 MV-RoboBench,这是首个专门评估视觉语言模型(VLMs)在机器人操作场景中多视角空间推理能力的基准测试
- 研究解决了现有VLM评估主要聚焦于单视角设置的问题,而多摄像头设置在机器人平台中越来越常见,可提供互补视角以缓解遮挡和深度歧义
- 基准包含1.7k个手动策划的问答项,涵盖八个子任务,分为两个主要类别:空间理解和机器人执行
Card 01
研究单位
研究单位
- 清华大学(Tsinghua University)
- 北京大学(Peking University)
- 复旦大学(Fudan University)
- 微软亚洲研究院(Microsoft Research Asia)
- 香港科技大学(Hong Kong University of Science and Technology)
- 浙江大学(Zhejiang University)
Card 02
论文概述
论文概述
- 论文提出了 MV-RoboBench,这是首个专门评估视觉语言模型(VLMs)在机器人操作场景中多视角空间推理能力的基准测试
- 研究解决了现有VLM评估主要聚焦于单视角设置的问题,而多摄像头设置在机器人平台中越来越常见,可提供互补视角以缓解遮挡和深度歧义
- 基准包含1.7k个手动策划的问答项,涵盖八个子任务,分为两个主要类别:空间理解和机器人执行
- 核心目标是评估VLM能否有效整合多视角输入信息以支持机器人决策
Card 03
核心贡献
核心贡献
- 建立了首个将空间推理和机器人执行与同步多视角输入整合的基准测试,用于机器人操作场景的全面评估
- 通过广泛实验表明最先进的VLM模型仍远低于人类表现,许多模型性能接近随机水平
- 探索了CoT(思维链)增强技术,产生了混合且依赖于模型的效果
- 发现两个关键结论:(i)空间智能与机器人任务执行呈正相关;(ii)现有通用单视角空间基准的强大性能不能可靠地转移到机器人任务或多视角空间推理任务
Card 04
方法描述
方法描述
- 数据来源:基于AgiWorld和BridgeV2数据集构建,包含单臂和双臂机器人操作设置
- 八个子任务:
- 空间理解类:跨视角匹配、距离判断、视角识别、3D空间一致性
- 机器人执行类:动作规划、步骤执行、轨迹选择、可供性识别
- CoT增强技术:探索了三种增强多视角理解的方法——文本增强(场景描述)、视觉增强(通过新视角合成)、结构增强(深度先验)
Card 05
数据集与资源
数据集与资源
- 数据集规模:1,708个多项选择题,来自980个机器人演示片段
- 评估模型:包括闭源模型(GPT-4o、GPT-4.1、Claude、Gemini、GPT-5等)和开源模型(Qwen2.5-VL、InternVL3、Gemma3、Llama4等)
- 人类基线:91.04%
Card 06
评估与结果
评估与结果
- 评估设置:统一的零样本提示
- 主要结果:
- GPT-5平均得分56.41%(最高),但仍远低于人类91.04%
- 开源模型中Qwen2.5-VL-72B表现最好(24.29%)
- 多数模型在3D空间一致性任务上表现最差(仅约5-20%)
- 随机基线约为19.71%
- 关键发现:空间推理与机器人执行能力呈正相关;单视角空间基准的表现不能转移到多视角机器人任务