一眼看懂
封面预览
研究目标是解决长时域机器人操作任务中 Vision-Language-Action (VLA) 策略的漂移和暴露偏差问题
- 研究目标是解决长时域机器人操作任务中 Vision-Language-Action (VLA) 策略的漂移和暴露偏差问题
- 核心问题:现有方法使用固定超参数对整个轨迹进行去噪,导致小几何误差在阶段间累积,且无法在测试时自适应分配计算资源
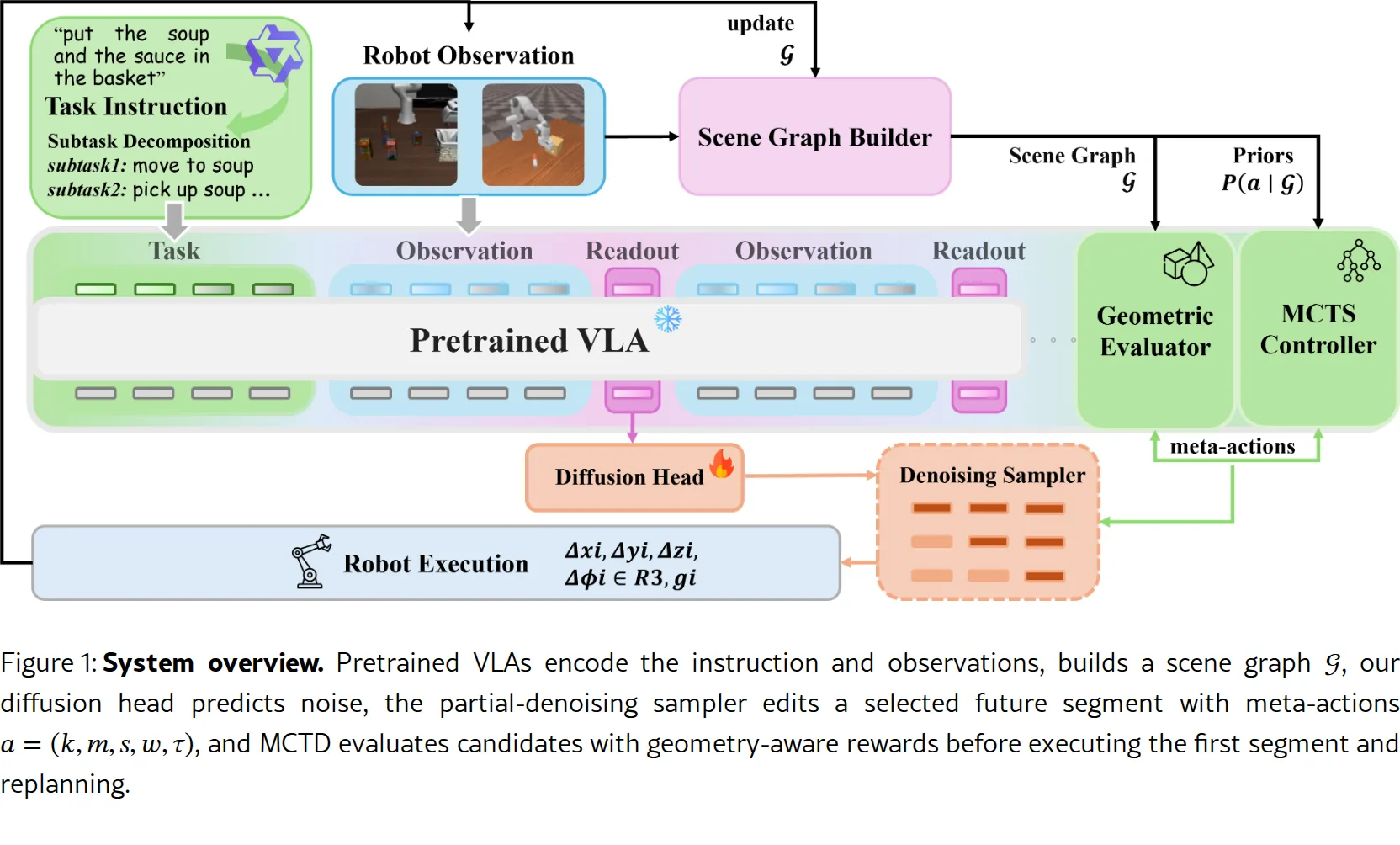
- 提出 FORGE-Tree:一种即插即用的控制层,结合阶段对齐的 Diffusion Forcing (DF) 头和测试时 Monte Car…
Card 01
研究单位
研究单位
- 德克萨斯农工大学(计算机科学与工程系):Yanjia Huang, Qingxiao Xu, Mingyang Wu, Xiangbo Gao, Zhengzhong Tu
- 华盛顿大学(电气与计算机工程系):Shuo Liu
- 德国卡尔斯鲁厄理工学院:Sheng Liu
Card 02
论文概述
论文概述
- 研究目标是解决长时域机器人操作任务中 Vision-Language-Action (VLA) 策略的漂移和暴露偏差问题
- 核心问题:现有方法使用固定超参数对整个轨迹进行去噪,导致小几何误差在阶段间累积,且无法在测试时自适应分配计算资源
- 提出 FORGE-Tree:一种即插即用的控制层,结合阶段对齐的 Diffusion Forcing (DF) 头和测试时 Monte Carlo Tree Diffusion (MCTD)
Card 03
核心贡献
核心贡献
- VLA 条件扩散头:使用 Transformer+FiLM 架构预测每个 token 的噪声,条件于 VLA 编码
- Diffusion Forcing 目标:将去噪调度与子任务结构对齐,使模型学习"着陆"子目标
- 树结构去噪:通过元动作(分段、步长、引导、温度)实现可扩展的自适应预算解码
- 双角色场景图:同时提供扩展先验和几何关系感知评估,连接符号与运动学
- 即插即用设计:作为控制层升级,不修改 VLA 主干,在 OpenVLA 和 Octo-Base 上均产生一致性能提升
Card 04
方法描述
方法描述
- Diffusion Forcing 训练:为每个子任务分配单一时间步,使同一阶段内的 token 共享噪声水平("噪声=掩码")
- 部分去噪推理:使用分段算子仅演化未来分段,同时冻结已执行前缀
- 几何关系感知引导:定义势函数 U 结合终端对齐、阶段锚定、关系违反惩罚和碰撞成本
- 阶段感知 MCTD:使用 P-UCT 选取引擎,双重奖励(快速启发式 vs 真实几何回报)指导搜索
Card 05
数据集与资源
数据集与资源
- 训练数据:EMMA-X(阶段标注的机器人操作轨迹)
- 评估基准:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-Long 和 ManiSkill
- VLA 主干:OpenVLA、Octo-Base(冻结,不微调)
- 训练资源:4×48GB Ada GPU,200k 步,每 GPU 批大小 64
Card 06
评估与结果
评估与结果
- LIBERO 基准:FORGE-Tree 在四个套件上取得显著改进
- OpenVLA 基线:76.5% → 89.9%(+13.4 pp)
- Octo-Base 基线:75.1% → 92.3%(+17.2 pp)
- 最长时域任务:LIBERO-Long 提升最大(OpenVLA +29.5 pp,Octo +39.9 pp)
- SOTA 对比:与离散扩散 VLA(96.3%)差距缩小至 4-6 pp
- 核心优势:作为即插控制层,在不修改编码器的情况下大幅提升 VLA 的长时域任务表现