一眼看懂
封面预览
提出 LITEN(Learning from Inference-Time Execution),一种无需额外训练即可让机器人从推理时执行中学…
- 提出 LITEN(Learning from Inference-Time Execution),一种无需额外训练即可让机器人从推理时执行中学…
- 解决视觉语言动作模型(VLAs)在复杂长程任务中缺乏上下文自适应能力的核心问题
- 通过两阶段迭代框架(推理阶段 + 评估阶段)实现对低层 VLA 能力的理解(affordances 学习)
Card 01
研究单位
研究单位
- UC Berkeley - 主要研究机构(作者包括 Ameesh Shah, William Chen, Adwait Godbole, Federico Mora, Sanjit A. Seshia)
- Physical Intelligence - 合作研究机构(Sergey Levine 所属)
Card 02
论文概述
论文概述
- 提出 LITEN(Learning from Inference-Time Execution),一种无需额外训练即可让机器人从推理时执行中学习的方法
- 解决视觉语言动作模型(VLAs)在复杂长程任务中缺乏上下文自适应能力的核心问题
- 通过两阶段迭代框架(推理阶段 + 评估阶段)实现对低层 VLA 能力的理解(affordances 学习)
Card 03
核心贡献
核心贡献
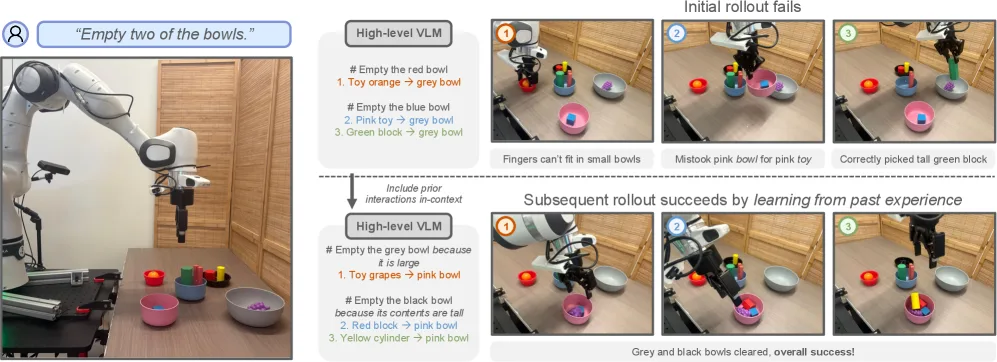
- 提出 LITEN 方法,允许高层 VLM 通过推理时与物理世界的交互来学习机器人的 affordances
- 设计结构化评估流程,通过多层提示链(subtask 成功与否 → 实际行为 → 失败原因推理)从非结构化视频轨迹中提取有用反馈
- 无需额外训练,可使用任意现成的 VLM 和 VLA,具有广泛的适用性
- 在三个真实机器人操作任务(Stacking、Emptying Bowls、Moving Off Table)上验证了方法的有效性
Card 04
方法描述
方法描述
- 高层 VLM(GPT-5-mini):作为推理器(reasoner),负责将长程任务分解为子任务指令序列
- 低层 VLA(π₀.₅-DROID):基于 DROID 数据集微调的视觉语言动作策略,负责执行具体子任务
- 两阶段迭代:
- 推理阶段:VLM 根据任务指令生成子任务计划,VLA 执行每个子任务
- 评估阶段:VLM 法官评估每个子任务执行结果,包括成功/失败判断、行为描述、失败原因分析
- 评估结果作为上下文反馈到下一次推理迭代,使 VLM 能逐步学习 VLA 的能力边界
Card 05
数据集与资源
数据集与资源
- 数据集:DROID 机器人操作数据集,用于 VLA 微调
- 实验任务:
- Stacking(堆叠任务)
- Emptying Bowls(清空碗任务)
- Moving Off Table(移出桌面任务)
- 训练数据:每个任务收集 150 条演示数据,用于微调 VLA
- 机器人平台:DROID Franka 设置(7-DoF Franka Emika Panda 机械臂 + 2F-85 Robotiq 夹爪)
Card 06
评估与结果
评估与结果
- 评估指标:完整任务成功率(五次迭代内),基于 10 次试验平均
- 主要结果:
- LITEN 随迭代次数增加持续提升成功率,显著优于基线方法
- No-Feedback 基线几乎无法完成任务,说明推理时学习的重要性
- 消融实验:
- 移除失败原因推理步骤后性能显著下降
- 仅保留成功/失败判断的版本表现最差
- 证明结构化评估流程的每个步骤都至关重要
- 关键发现:LITEN 特别擅长从两类失败中学习:(1)VLA 的语言指令偏好偏差;(2)物理属性导致的控制困难