一眼看懂
封面预览
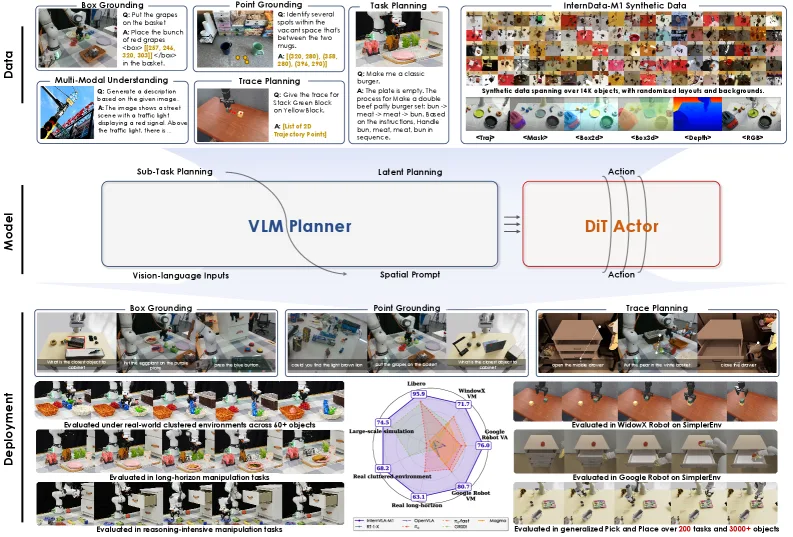
提出 InternVLA-M1,一个统一的视觉-语言-动作框架,通过空间引导的视觉-语言-动作训练将空间 grounding 作为连接指令与机…
- 提出 InternVLA-M1,一个统一的视觉-语言-动作框架,通过空间引导的视觉-语言-动作训练将空间 grounding 作为连接指令与机…
- 核心思路:空间 grounding 预训练确定"在哪里行动"(where to act),然后通过空间提示(spatial prompting…
- 目标:实现可扩展的、通用目的的指令跟随机器人智能
Card 01
研究单位
研究单位
- Intern Robotics
- 上海人工智能实验室 (Shanghai AI Laboratory)
Card 02
论文概述
论文概述
- 提出 InternVLA-M1,一个统一的视觉-语言-动作框架,通过空间引导的视觉-语言-动作训练将空间 grounding 作为连接指令与机器人动作的关键桥梁
- 核心思路:空间 grounding 预训练确定"在哪里行动"(where to act),然后通过空间提示(spatial prompting)生成具体动作决定"如何行动"(how to act)
- 目标:实现可扩展的、通用目的的指令跟随机器人智能
##核心贡献
- 提出两阶段空间引导训练配方:第一阶段在超过 230 万空间推理数据上进行空间 grounding 预训练,第二阶段进行空间引导的动作后训练
- 设计双系统架构:VLM Planner(System 2,慢速可靠推理者)+ Action Expert(DiT Actor,System 1,快速执行者)
- 构建可扩展的合成数据引擎,生成 24.4 万个通用化 pick-and-place 场景,支持 200 个任务和 3000+ 物体
- 在 SimplerEnv Google Robot 上比无空间引导版本提升 +14.6%,在 WidowX 上提升 +17%,在 LIBERO Franka 上提升 +4.3%
- 在真实世界杂乱场景 pick-and-place 中提升 +7.3%,在未见物体和新配置下达到 +20.6% 提升
Card 03
方法描述
方法描述
- 模型架构:采用 Qwen2.5-VL-3B-instruct 作为多模态编码器(System 2),扩散策略(86M 参数)作为动作专家(System 1),总参数量约 4.1B
- 空间提示(Spatial Prompting):在任务指令后附加空间提示如"Figure out how to execute it, then locate the key object needed"以激活空间感知能力
- 两阶段训练:
- 阶段 1:仅优化 VLM,在大规模多源多模态空间 grounding 数据上进行预训练
- 阶段 2:VLM 和 Action Expert 联合优化,使用空间提示和空间 grounding 数据协同训练
- 梯度衰减因子:在查询变换器中引入 0.5 的梯度衰减,防止动作专家的梯度破坏 VLM 的语义推理能力
Card 04
数据集与资源
数据集与资源
- 预训练数据:超过 300 万多模态训练样本,其中 230 万为空间推理数据
- General QA: 约 63.7 万样本
- Box QA: 约 87.9 万样本
- Trajectory QA: 约 68.4 万样本
- Point QA: 约 83.2 万样本
- 合成数据:InternData-M1 数据集,包含 24.4 万 个闭环 pick-and-place 样本
- 资产库:1.4 万标注物体、211 张桌子、1600 种纹理、87 个 dome lights
- 训练资源:16 张 NVIDIA A100 GPU,50k 步训练(约 2.5 个 epoch)
- 推理资源:单张 RTX 4090 GPU,约 12 GB 显存,VLM 推理速度约 10 FPS
Card 05
评估与结果
评估与结果
- SimplerEnv 基准:
- Google Robot Visual Matching: 95.3%(提升 +14.6%)
- Google Robot Visual Aggregation: 75.5%(提升 +12.4%)
- WidowX Visual Matching: 71.7%(提升 +17.0%)
- LIBERO 基准:
- Spatial: 98.0%,Objects: 99.0%,Goal: 93.8%,Long: 92.6%,平均 95.9%
- 大规模模拟 pick-and-place:200 个任务,平均提升 +6.2% 相比 GR00T N1.5
- 真实世界杂乱场景:
- 未见物体和配置:提升 +20.6%
- 长期推理任务:超越现有工作超过 10%