一眼看懂
封面预览
提出了 Embedding Disruption Patch Attack (EDPA),首个针对 Vision-Language-Actio…
- 提出了 Embedding Disruption Patch Attack (EDPA),首个针对 Vision-Language-Actio…
- 开发了基于视觉编码器对抗微调 (Adversarial Fine-tuning) 的防御策略,使 VLA 模型能够抵御此类对抗攻击
- 在 LIBERO 机器人仿真基准上验证了攻击的有效性:EDPA 能将 OpenVLA 的任务失败率提升约 74.7%,同时证明所提防御方法能显…
Card 01
研究单位
研究单位
- The University of Auckland(奥克兰大学)- Haochuan Xu, Yun Sing Koh, Shuhuai Huang, Zirun Zhou, Jingfeng Zhang
- King Abdullah University of Science and Technology(阿卜杜拉国王科技大学)- Di Wang, Jingfeng Zhang
- Tokyo University of Science(东京理科大学)- Jun Sakuma
- RIKEN Center for Advanced Intelligence Project(理研 AIP 中心)- Jun Sakuma, Jingfeng Zhang
Card 02
论文概述
论文概述
- 提出了 Embedding Disruption Patch Attack (EDPA),首个针对 Vision-Language-Action (VLA) 模型的模型无关对抗补丁攻击方法,无需了解目标模型架构即可生成攻击补丁
- 开发了基于视觉编码器对抗微调 (Adversarial Fine-tuning) 的防御策略,使 VLA 模型能够抵御此类对抗攻击
- 在 LIBERO 机器人仿真基准上验证了攻击的有效性:EDPA 能将 OpenVLA 的任务失败率提升约 74.7%,同时证明所提防御方法能显著降低失败率
Card 03
核心贡献
核心贡献
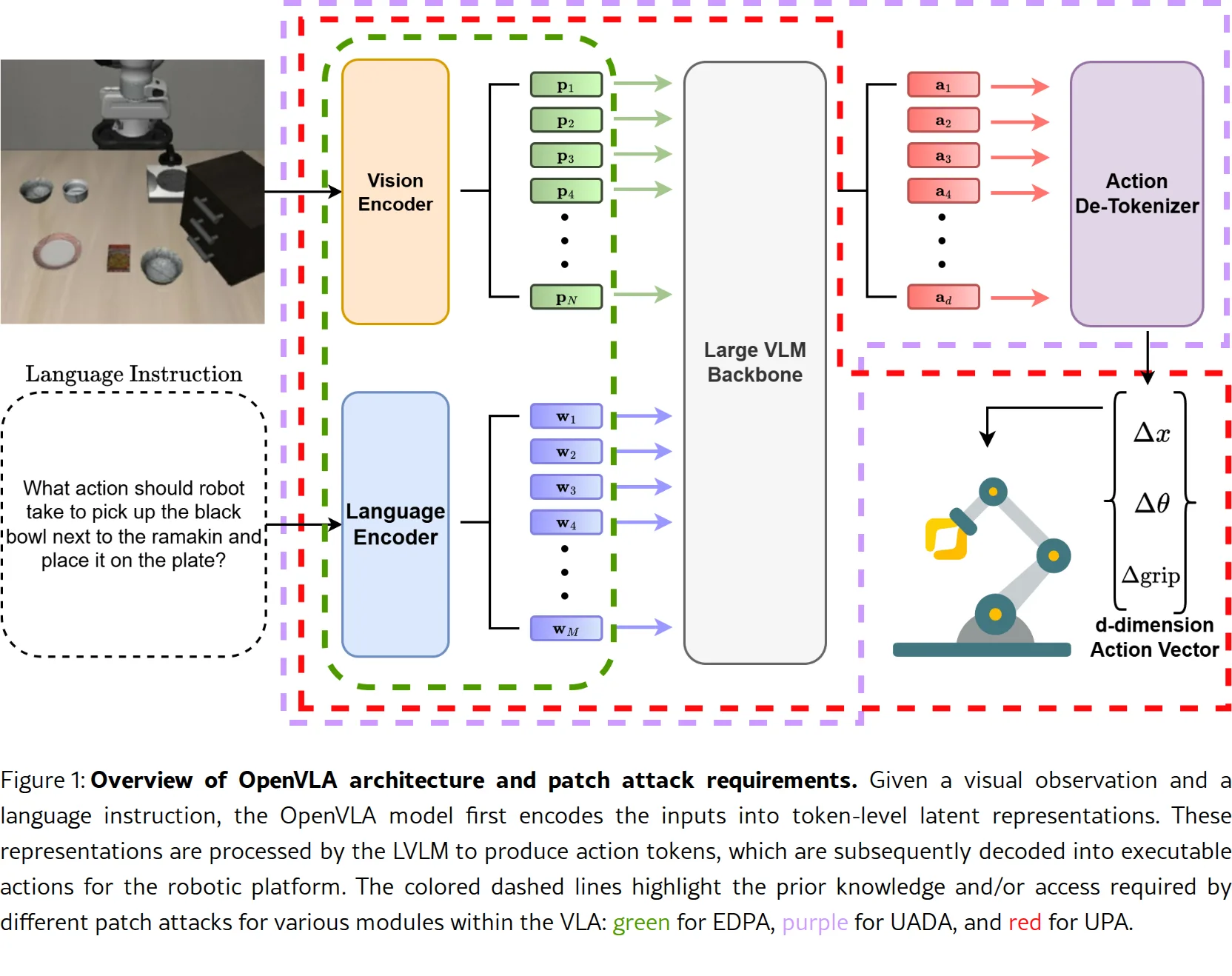
- EDPA 攻击方法:通过破坏视觉与文本潜在表示之间的语义对齐,以及最大化对抗样本与干净样本之间的潜在表示差异,生成可直接放置在相机视野中的对抗补丁
- 模型无关性:与之前需要了解模型架构和机械臂参数的 UADA 和 UPA 攻击不同,EDPA 仅需访问编码器参数,更适用于实际场景
- 对抗微调防御:提出视觉编码器的对抗微调方案,鼓励编码器为对抗视觉输入生成与干净输入相似的潜在表示
- 广泛的评估:在多种 SOTA VLA 模型(OpenVLA、OpenVLA-OFT、π₀)上验证了攻击和防御的有效性
- 注意力可视化分析:通过展示对抗补丁如何改变语言 token 对视觉输入的注意力分布,揭示攻击机制
Card 04
方法描述
方法描述
- EDPA 攻击:优化目标结合两个损失函数——(1) Patch Contrastive Loss(补丁对比损失):衡量干净与对抗视觉输入之间的图像块嵌入差异;(2) Image-Instruction Alignment Loss(图像-指令对齐损失):衡量加入补丁后视觉与语言表示对齐的变化
- 优化公式:δ* = argmax_δ E_{v~D}[α₁·L_patch + (1-α₁)·L_align],通过梯度上升更新对抗补丁
- 防御方法:使用原始视觉编码器作为基准,通过最小化两个目标的加权组合来微调新编码器——(1) 干净输入的表示应与原始编码器相似;(2) 对抗输入的表示也应接近原始编码器对干净输入的表示
- 训练策略:在 EDPA 训练过程中周期性地重新初始化对抗补丁,以防止过拟合到特定补丁
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 机器人仿真基准,包含四个任务套件(Spatial、Object、Goal、Long),每个任务套件有 10 个任务
- 评估模型:OpenVLA、OpenVLA-OFT、π₀(均为在 LIBERO 上微调后的模型)
- 补丁尺寸:50×50 像素(固定),输入图像分辨率 224×224
- 训练配置:最大迭代次数 T=50,000,批量大小 16,学习率 η=1×10⁻⁵,α₁=0.8(攻击),α₂=0.5(防御)
Card 06
评估与结果
评估与结果
- 评估指标:Failure Rate (FR) 失败率 = 1 - 成功率
- 攻击效果:
- OpenVLA 在 EDPA 攻击下平均失败率从 14.1%-48.1%(干净)提升至 100%
- OpenVLA-OFT:EDPA 使平均失败率提升约 62.0%
- π₀:EDPA 使平均失败率提升约 31.4%
- 防御效果:
- 对抗微调后,OpenVLA 在 EDPA 攻击下的失败率平均降低 34.2%
- 对 UADA 和 UPA 攻击的失败率也分别降低 19.1% 和 36.0%
- 干净输入下失败率仅增加约 1.6%(权衡取舍)
- 与基线对比:EDPA 明显优于随机噪声补丁,OpenVLA 在 EDPA 下失败率比随机噪声高约 53.0%
- 多相机设置:使用多相机视角的 VLA 模型(OpenVLA-OFT、π₀)表现出更强的对抗鲁棒性