一眼看懂
封面预览
提出 Reflective Self-Adaptation 框架,解决预训练 Vision-Language-Action (VLA) 模型在…
- 提出 Reflective Self-Adaptation 框架,解决预训练 Vision-Language-Action (VLA) 模型在…
- 核心挑战:现有 VLA 模型在部署到新环境时初始成功率低,强化学习样本效率差,导致任务精通过程漫长而困难
- 框架建立自改进闭环,通过从自身失败和成功中学习来协同提升策略和执行能力
Card 01
研究单位
研究单位
- 北京大学智能科学与技术学院 (Peking University)
- 京东探索研究院 (JD Explore Academy)
- 清华大学智能产业研究院 (AIR, Tsinghua University)
Card 02
论文概述
论文概述
- 提出 Reflective Self-Adaptation 框架,解决预训练 Vision-Language-Action (VLA) 模型在新环境中的快速适应问题,无需人工干预即可实现自主任务学习
- 核心挑战:现有 VLA 模型在部署到新环境时初始成功率低,强化学习样本效率差,导致任务精通过程漫长而困难
- 框架建立自改进闭环,通过从自身失败和成功中学习来协同提升策略和执行能力
Card 03
核心贡献
核心贡献
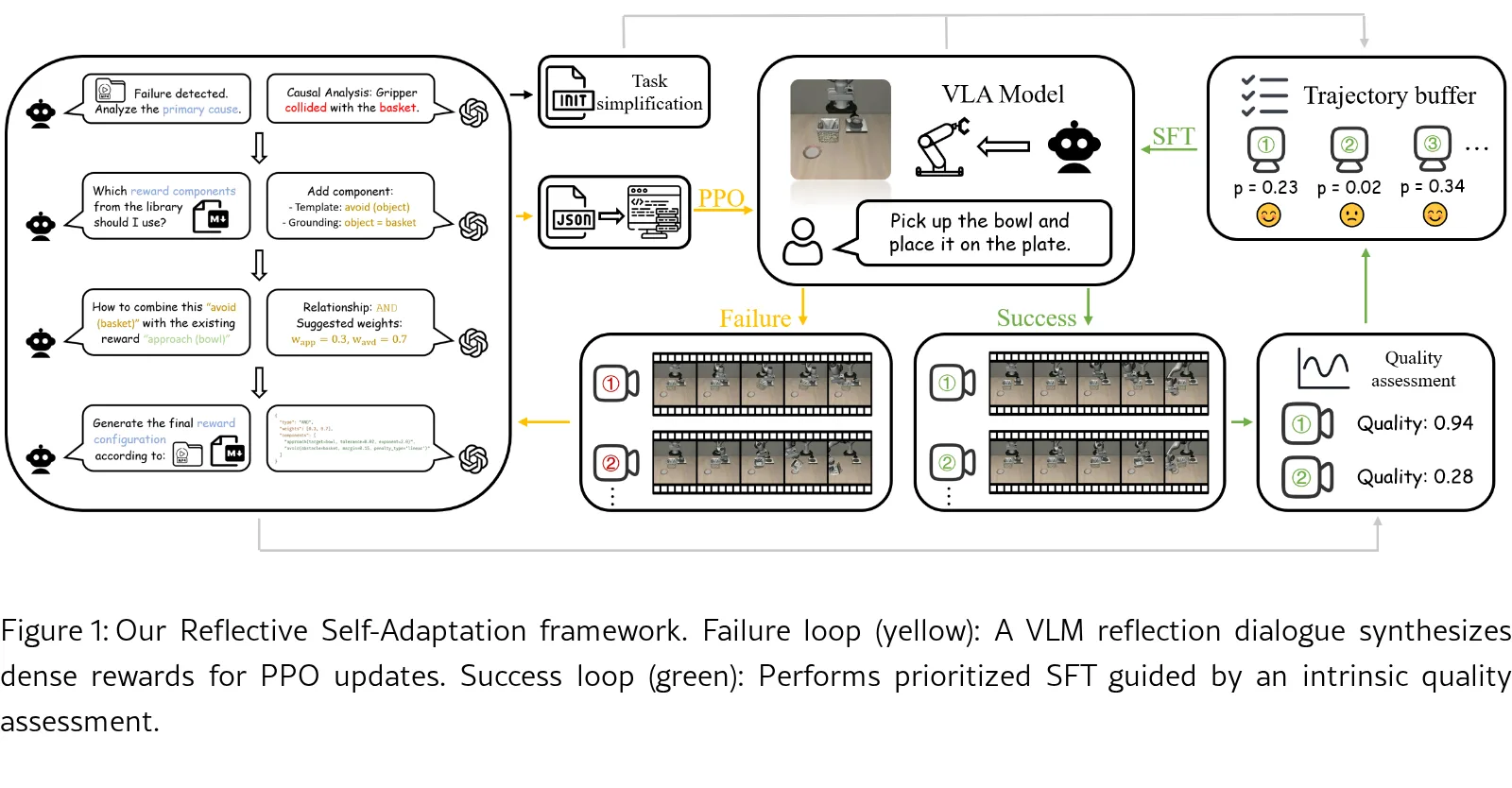
- 提出 Reflective Self-Adaptation 框架,一种新型双路径架构,实现 VLA 的自主现场自适应,系统性地从失败和成功中学习,实现快速稳健的任务掌握
- 引入 Failure-Driven Reflective RL 路径,围绕 Reflective Reward Synthesis 方法,利用 VLM 的因果推理从失败分析自动生成密集奖励
- 设计互补的 Success-Driven Quality-Guided SFT 路径,通过选择性模仿高质量成功轨迹来稳定学习并确保目标对齐,通过内在质量评估和 VLM 驱动的课程缓解奖励黑客和冷启动探索风险
Card 04
方法描述
方法描述
- Reflective Reward Synthesis:使用 VLM 进行四阶段推理(因果分析→组件选择→关系识别→结构化配置生成),构建模块化奖励函数
- 奖励组件库:包含位置组件(如 approach, avoid, maintain_distance)、姿态组件、运动学组件、状态组件
- 关系处理器:AND(加权求和)、IF(条件调制)、OR(最大选择)用于组合奖励组件
- 策略优化:使用 PPO 算法,结合 GAE 估计优势函数
- 质量引导 SFT:基于累积反射奖励和轨迹长度计算质量分数,使用优先经验回放采样
- 条件课程机制:当主任务成功率低于阈值时,激活课程学习生成简化任务
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 基准(4个子集:Spatial, Object, Goal, Long)、LIBERO-Adapt(自定义困难任务套件,10个场景)
- 基础模型:OpenVLA-7B
- VLM:GPT-4o 用于反思推理
- 训练资源:8 张 A800 GPU,每 5 轮执行一次反思过程
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO 模拟器
- 主要指标:成功率 (Success Rate)
- 关键结果:
- LIBERO 四个子集平均成功率达 83.6%,超越 VLA-RL (81.0%) 等基线
- LIBERO-Adapt 上收敛速度显著快于 VLA-RL 和 Sparse RL 基线
- 消融实验表明去除任一核心组件均导致性能下降,去除 Success-Driven SFT 完全失败 (0.0%)