一眼看懂
封面预览
DEAS 是一种离线强化学习框架,利用动作序列(action sequence)进行价值学习,以应对复杂的长程决策任务
- DEAS 是一种离线强化学习框架,利用动作序列(action sequence)进行价值学习,以应对复杂的长程决策任务
- 该方法解决了在离线 RL 中使用动作序列时出现的价值过度估计问题,通过解耦价值学习与策略更新来保持训练稳定性
- 方法可与大型视觉-语言-动作模型(VLAs)结合,在模拟和真实机器人任务上显著提升性能
Card 01
研究单位
研究单位
- KAIST (韩国科学技术院)
- UC Berkeley (加州大学伯克利分校)
- University of Texas at Austin (德克萨斯大学奥斯汀分校)
- NVIDIA (英伟达)
Card 02
论文概述
论文概述
- DEAS 是一种离线强化学习框架,利用动作序列(action sequence)进行价值学习,以应对复杂的长程决策任务
- 该方法解决了在离线 RL 中使用动作序列时出现的价值过度估计问题,通过解耦价值学习与策略更新来保持训练稳定性
- 方法可与大型视觉-语言-动作模型(VLAs)结合,在模拟和真实机器人任务上显著提升性能
Card 03
核心贡献
核心贡献
- 提出 DEAS (DEtached value learning with Action Sequence):一种利用动作序列的离线 RL 方法,采用分离式价值学习避免价值过度估计
- 在 OGBench 的 30 个多样化任务场景中显著优于现有基线方法
- 展示了 DEAS 可用于增强大规模 Vision-Language-Action (VLA) 模型的性能,在 RoboCasa Kitchen 和真实机器人操作任务上取得优异结果
Card 04
方法描述
方法描述
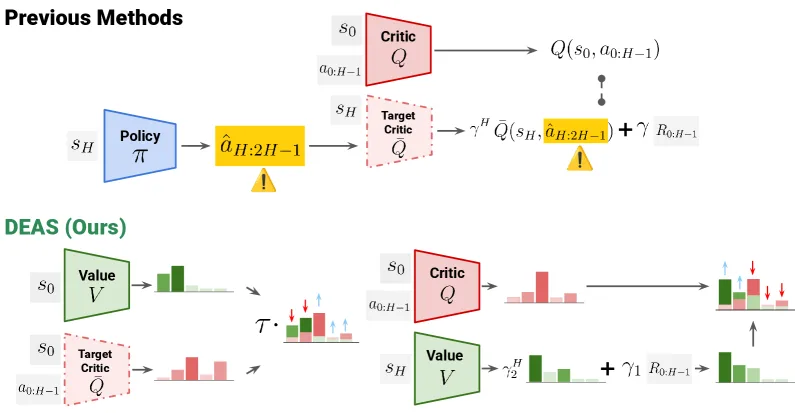
- 选项框架(Options Framework):将 H 步动作序列建模为单一决策单元,诱导半马尔可夫决策过程(SMDP),实现有效的规划视界缩减
- 分离式价值学习(Detached Value Learning):借鉴 IQL 方法,将评论家训练与演员解耦,使用分类损失训练价值网络,偏向离线数据集中的高回报动作
- 分布强化学习(Distributional RL):将评论家和价值网络建模为离散分布,增强多步返回累积偏差下的稳定性
- 双折扣因子:γ₁ 用于选项内(intra-option)奖励,γ₂ 用于选项间(inter-option)奖励,缓解价值爆炸或崩溃问题
Card 05
数据集与资源
数据集与资源
- OGBench:6 个操作环境(scene-play、cube-double-play、puzzle-3x3、cube-triple-play、puzzle-4x4、cube-quadruple-play),每个环境 5 个子任务
- RoboCasa Kitchen:4 个具有挑战性的操作任务
- 真实机器人实验:Franka Emika Research 3 机械臂
- 使用 GR00T N1.5 VLA 模型进行微调实验
Card 06
评估与结果
评估与结果
- 评估基准:OGBench 离线 RL 基准测试
- 主要指标:成功率(%)
- 关键结果:
- 在 puzzle-3x3-play 任务上:DEAS 达到 91% 成功率,显著领先于 FQL (44%)、n-step FQL (36%)、QC-FQL (62%)
- 在 scene-play 任务上:DEAS 达到 76%,领先于 FQL (50%)、n-step FQL (36%)、QC-FQL (73%)
- 在 cube-triple-play 任务上:DEAS 达到 82%,大幅领先于其他方法
- 消融实验验证了动作序列长度、网络规模、训练目标和双折扣因子的有效性