一眼看懂
封面预览
提出 MimicDreamer 框架,将低成本的人类演示视频转化为可用的机器人监督数据,解决机器人数据收集成本高的问题
- 提出 MimicDreamer 框架,将低成本的人类演示视频转化为可用的机器人监督数据,解决机器人数据收集成本高的问题
- 该框架同时解决人类与机器人演示之间的三个关键差距:视角差异、动作差异和视觉差异
- 核心目标是通过大规模人类演示数据实现可扩展的 VLA(视觉语言动作)模型训练
Card 01
研究单位
研究单位
- GigaAI
- CASIA (中国科学院自动化研究所)
- NJUST (南京理工大学)
- 清华大学
Card 02
论文概述
论文概述
- 提出 MimicDreamer 框架,将低成本的人类演示视频转化为可用的机器人监督数据,解决机器人数据收集成本高的问题
- 该框架同时解决人类与机器人演示之间的三个关键差距:视角差异、动作差异和视觉差异
- 核心目标是通过大规模人类演示数据实现可扩展的 VLA(视觉语言动作)模型训练
Card 03
核心贡献
核心贡献
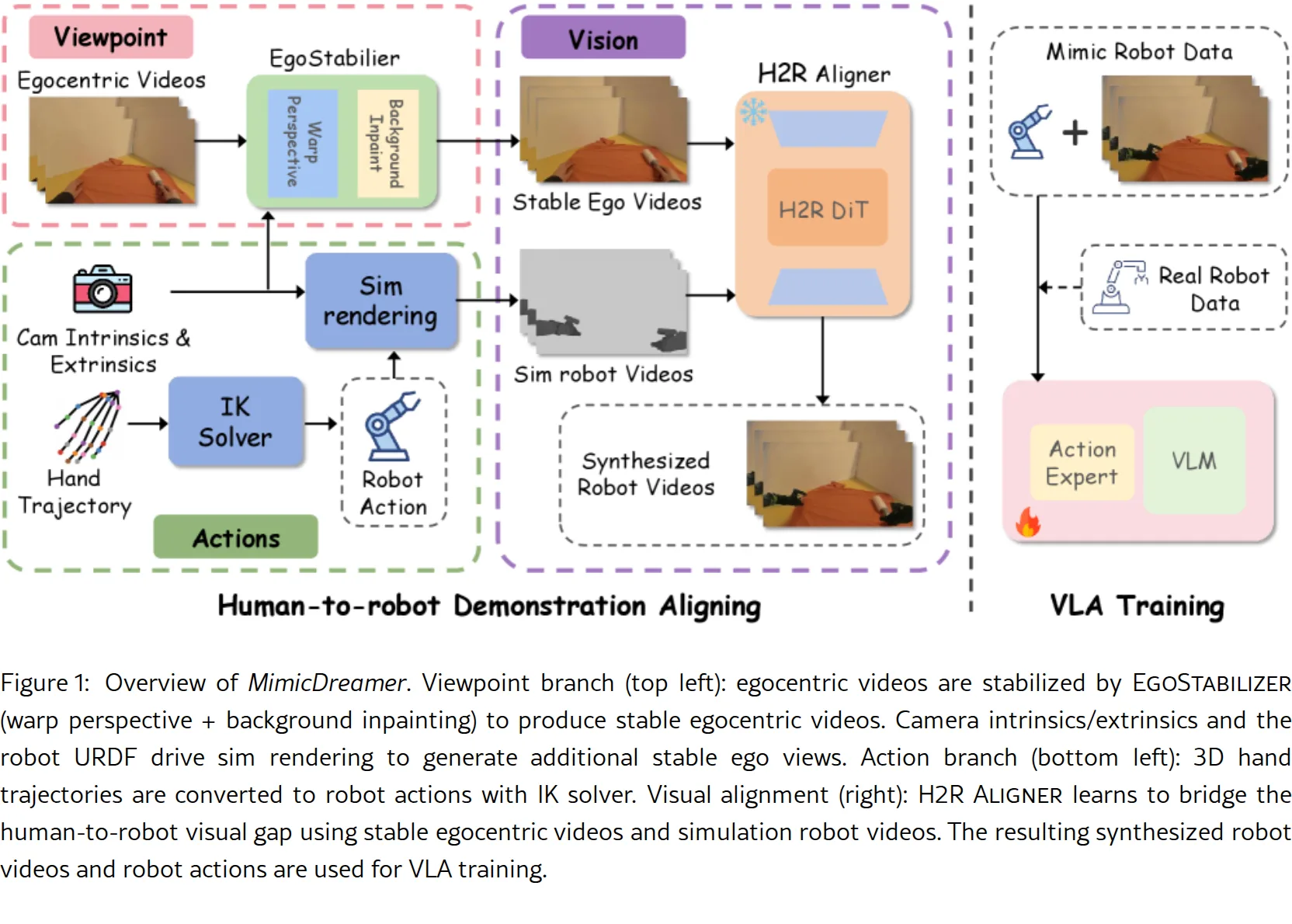
- 提出统一的 MimicDreamer 框架,同时在视觉、视角和动作三个维度上缩小人类到机器人的差距
- 开发 H2R Aligner,基于视频扩散模型和几何相机先验合成高保真的机械臂视频
- 开发 EgoStabilizer,通过单应性变换将egocentric视频规范化为任务参考视图,并修复变形引起的遮挡
- 动作对齐:建立统一的 H2R 动作空间,通过约束逆运动学(IK)求解器生成可行、低抖动的关节命令
- VLA策略仅在合成的人类-机器人视频上训练即可实现真实机器人的少样本执行,在六个任务上平均成功率提升 14.7%
Card 04
方法描述
方法描述
- 视角稳定化(EgoStabilizer):使用Warp Perspective进行特征匹配和单应性估计,通过时间平滑减少高频抖动,然后使用视频修复模型填充遮挡区域
- 动作对齐:在身体中心坐标系表达人类3D关键点,通过刚性变换映射到机器人基座;仅对齐俯仰/偏航角(软屏蔽翻转);使用阻尼最小二乘法(DLS)求解约束IK问题
- 视觉对齐(H2R Aligner):基于CogVideoX-5b-I2V构建,将真实机器人视频、背景场景和模拟前景编码后连接,输入到H2R DiT进行潜在空间去噪和条件融合
- VLA训练:从π0预训练模型初始化,使用条件流匹配目标(Conditional Flow Matching)进行动作token监督
Card 05
数据集与资源
数据集与资源
- 使用 EgoDex 数据集,包含829小时的1080p egocentric视频,配合194个任务的3D上半身姿态数据
- H2R Aligner在24个操作类别上训练,共3,735个样本(每个64帧,30fps)
- 评估任务:Pick Bag、Clean Surface、Stack Bowls、Dry Hands、Insert Tennis、Stack Cups
Card 06
评估与结果
评估与结果
- 评估指标:Success Rate (SR) 和 Progress Success Rate (PSR)
- 少样本实验结果:
- Robot Only基线:65.8% SR / 76.3% PSR
- w. Minimal Robot(20人类数据+3机器人数据):70.0% SR / 81.0% PSR
- w. Equal Data(20人类数据+20机器人数据):85.0% SR / 91.0% PSR
- 缩放实验:随着人类演示数据量增加,所有六个任务的SR和PSR单调上升,在50-50混合比例下相比基线提升11.0%-32.0%
- EgoStabilizer效果:平均降低21.9%的稳定性误差和13.1%的抖动,同时仅增加3.3%的几何误差