一眼看懂
封面预览
研究针对 Vision-Language-Action (VLA) 模型在机器人操作中的高效推理问题,旨在减少长时序多模态上下文中的计算成本
- 研究针对 Vision-Language-Action (VLA) 模型在机器人操作中的高效推理问题,旨在减少长时序多模态上下文中的计算成本
- 核心问题:现有方法忽略了机器人操作不同阶段视觉 token 的冗余程度差异——粗粒度操作阶段(如移动)冗余度高,细粒度操作阶段(如抓取)冗余度低
- 提出 Action-aware Dynamic Pruning (ADP)框架,通过结合文本驱动的 token 选择与动作感知的轨迹门控,实现…
Card 01
研究单位
研究单位
- School of Computer Science, The University of Sydney(悉尼大学计算机科学学院)
Card 02
论文概述
论文概述
- 研究针对 Vision-Language-Action (VLA) 模型在机器人操作中的高效推理问题,旨在减少长时序多模态上下文中的计算成本
- 核心问题:现有方法忽略了机器人操作不同阶段视觉 token 的冗余程度差异——粗粒度操作阶段(如移动)冗余度高,细粒度操作阶段(如抓取)冗余度低
- 提出 Action-aware Dynamic Pruning (ADP)框架,通过结合文本驱动的 token 选择与动作感知的轨迹门控,实现自适应的动态剪枝
Card 03
核心贡献
核心贡献
- 发现 VLA 模型中视觉 token 的重要性在机器人操作的不同阶段会动态变化,这一观察为动态剪枝方法提供了理论基础
- 提出文本驱动的动作感知剪枝,将任务指令相关性评估与末端执行器运动门控相结合,实现剪枝状态与完整视觉状态的自适应切换
- 引入窗口轨迹距离 (Windowed Trajectory Distance) 机制,通过比较当前动作幅度与历史统计量来动态决定是否启用剪枝
- 提供有原则的计算复杂度分析,推导出预期 FLOPs 节省公式
- 在 LIBERO 模拟环境和真实机器人平台上进行广泛验证
Card 04
方法描述
方法描述
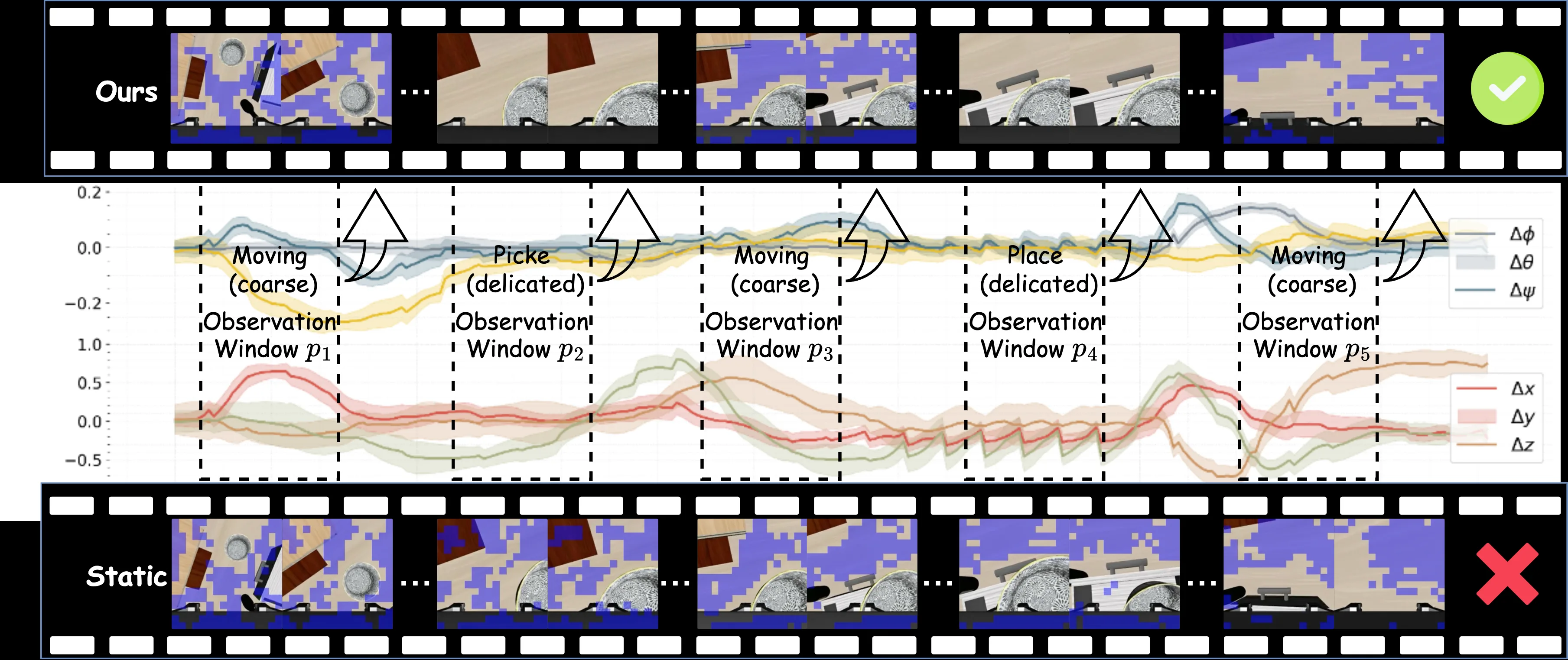
- 文本驱动的预见性剪枝 (Text-driven Anticipatory Pruning):在 LLM 之前计算视觉 token 与文本指令的跨模态相似度,通过公式 (7)-(10) 计算每个视觉 token 的重要性分数 Φ,然后保留 Top-K 个最相关的 token
- 动作感知的动态策略 (Action-Aware Dynamic Strategy):
- 将每个动作分块视为时间窗口,计算窗口内的末端执行器轨迹距离 δ_i(公式 15)
- 使用二元状态变量 s_i:s_i=0 表示完整视觉(不剪枝),s_i=1 表示剪枝状态
- 动态决策函数(公式 16)比较当前 δ_i 与历史平均值,或使用邻域极值函数(公式 17-18)实现快速状态切换
- 复杂度分析:剪枝在嵌入层执行,缩短的序列长度 S' 使所有 H 层 Transformer 层均受益
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO benchmark(含 Spatial、Object、Goal、Long 四个子集)
- 基础模型:OpenVLA-OFT (7B 参数)
- 训练/推理硬件:NVIDIA RTX 4090
- 真实机器人平台:Jaco2 机械臂
- 多视角设置:场景相机 + 手腕/夹爪相机
Card 06
评估与结果
评估与结果
- LIBERO 模拟实验:
- VLA-ADP (Ratio=50%):平均成功率 96.3%,FLOPs 从 7.91 降至 6.43,加速 1.23×
- VLA-ADP (Ratio=30%):平均成功率 94.4%,加速 1.35×
- Spatial 子集达到 99.4% 成功率
- 真实世界实验(4 项任务):
- 平均成功率从 85.8% 提升至 88.3%
- 延迟从 76.9ms 降至 51.8ms,加速 1.49×
- 消融实验:动作感知动态策略使平均 SR 提升 +2.85 个百分点;使用第 0 层计算重要性分数可获得最佳精度-计算平衡