一眼看懂
封面预览
提出一种基于扩散模型强化学习(Diffusion RL)的数据生成框架,用于为视觉-语言-动作(VLA)模型生成高质量合成训练数据
- 提出一种基于扩散模型强化学习(Diffusion RL)的数据生成框架,用于为视觉-语言-动作(VLA)模型生成高质量合成训练数据
- 解决VLA模型依赖大规模人工演示数据、收集成本高昂且数据质量不一致的核心问题
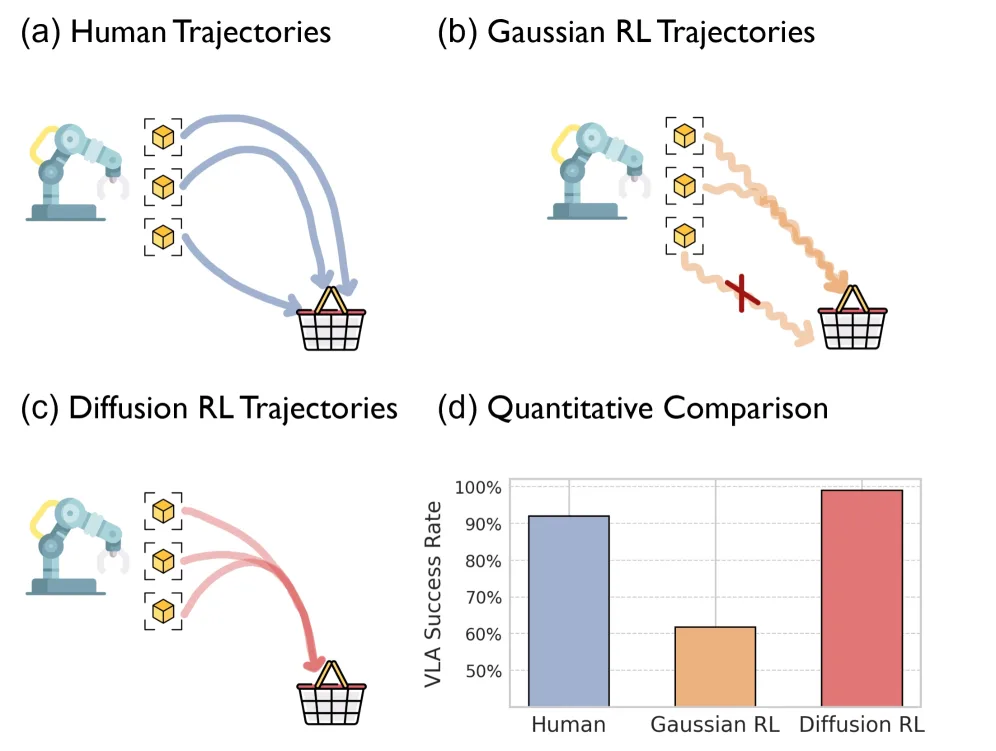
- 通过改进的扩散策略优化算法,生成比人工演示和传统高斯RL更平滑、低方差、最优的轨迹
Card 01
研究单位
研究单位
- Hong Kong University of Science and Technology (香港科技大学)
- Microsoft Research Asia (微软亚洲研究院)
- Wuhan University (武汉大学)
- University of Chinese Academy of Sciences (中国科学院大学)
- Tsinghua University (清华大学)
- Big Data Institute, Central South University (中南大学大数据研究院)
Card 02
论文概述
论文概述
- 提出一种基于扩散模型强化学习(Diffusion RL)的数据生成框架,用于为视觉-语言-动作(VLA)模型生成高质量合成训练数据
- 解决VLA模型依赖大规模人工演示数据、收集成本高昂且数据质量不一致的核心问题
- 通过改进的扩散策略优化算法,生成比人工演示和传统高斯RL更平滑、低方差、最优的轨迹
Card 03
核心贡献
核心贡献
- 提出扩散RL驱动的VLA训练流程,包含有效的模型架构改进和训练策略,实现稳定的数据生成
- 在LIBERO基准的130个复杂操作任务上验证,证明合成数据在分布内成功率(+5.3%)和分布外泛化上均优于人工数据
- 深入定量分析轨迹质量(效率、平滑性、一致性),揭示优化数据更有效的机制
- 证明人工数据与扩散RL数据的协同作用,混合数据在OOD任务上实现性能翻倍
Card 04
方法描述
方法描述
- 两阶段训练范式:(1)多模态行为克隆作为热启动,利用扩散模型捕获人类演示的多模态分布;(2)在线PPO强化学习微调,将去噪过程视为子轨迹决策
- 关键技术创新:
- ResNet+U-Net架构:ResNet提供样本效率,U-Net建模多模态数据,FiLM机制稳定条件信号
- DDIM采样器:5步确定性去噪替代DDPM,加速10倍并降低动作方差
- 余弦退火学习率:平衡探索与收敛稳定性
- 多样化经验回放:大规模并行环境防止模式坍塌
Card 05
数据集与资源
数据集与资源
- LIBERO基准:130个长程稀疏奖励操作任务,包含LIBERO-Spatial、Object、Goal、Long、90等子集
- VLA模型:基于π₀架构进行微调
- 数据规模:每任务50条轨迹,对比人工数据、高斯RL数据、扩散RL数据及混合数据
- 评估设置:每任务50次评估,OOD评估在30个未见任务上进行零样本测试
Card 06
评估与结果
评估与结果
- 主要指标:任务成功率(Success Rate)
- 分布内性能(表I):扩散RL数据平均成功率81.94%,较人工数据(76.64%)提升+5.3%,较高斯RL(69.32%)提升+12.6%
- 分布外泛化(表II):纯人工或纯RL数据OOD性能有限(1.47%-2.06%),人工+扩散RL混合数据达5.20%,实现互补增益
- 消融实验(图5):验证ResNet+U-Net、DDIM采样器、余弦退火学习率、高多样性回放缓冲区的关键作用
- 数据质量分析(图6-7):扩散RL数据在任务效率(最短轨迹)、轨迹平滑性(最低均方急动度)、动作一致性(最低方差)上全面最优