一眼看懂
封面预览
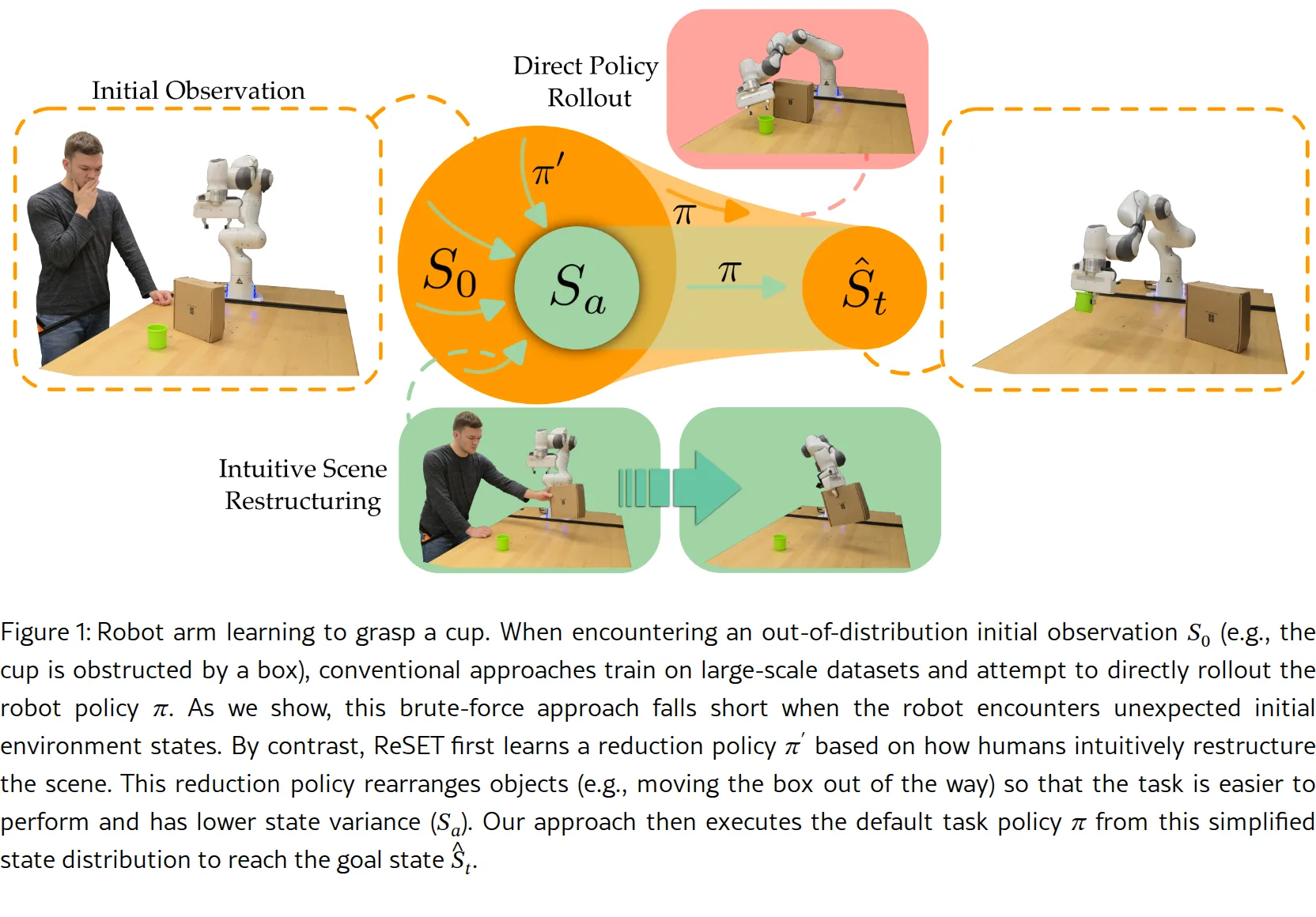
研究如何让机器人像人类一样,在执行任务前先重组环境(rearrange initial states),以提高在分布外(out-of-dist…
- 研究如何让机器人像人类一样,在执行任务前先重组环境(rearrange initial states),以提高在分布外(out-of-dist…
- 提出 ReSET(Restructuring States for Efficient policy Training)算法,使机器人能够在执…
- 核心问题:传统模仿学习策略在遇到意外初始状态(如物体被遮挡、位置异常)时容易失败,通常需要大量训练数据才能解决
Card 01
研究单位
研究单位
- Virginia Tech - Department of Mechanical Engineering, Collaborative Robotics Lab (Collab), Blacksburg, VA
- 作者:Yinlong Dai, Andre Keyser, Dylan P. Losey
- 资助:NSF Grant #2337884
Card 02
论文概述
论文概述
- 研究如何让机器人像人类一样,在执行任务前先重组环境(rearrange initial states),以提高在分布外(out-of-distribution)状态下的泛化能力
- 提出 ReSET(Restructuring States for Efficient policy Training)算法,使机器人能够在执行任务策略前先修改场景,将初始状态转化为更易处理的"锚定状态"(anchor states)
- 核心问题:传统模仿学习策略在遇到意外初始状态(如物体被遮挡、位置异常)时容易失败,通常需要大量训练数据才能解决
Card 03
核心贡献
核心贡献
- 理论贡献:证明学习"约简策略"(reduction policy)可以降低策略的泛化误差上界,并在相同数据量下实现更好的性能
- 方法创新:提出基于流(flow-based)的约简策略,从动作无关的人类视频和任务无关的机器人play数据中学习重组环境的策略
- 算法框架:ReSET包含三个关键组件——评分网络(决定何时重组)、流生成网络(预测物体运动)、约简策略(将预测转化为机器人动作)
- 数据效率:实验表明ReSET只需约10分钟人工修正+20分钟机器人play数据,而扩散策略需要至少70个专家演示才能达到类似性能
Card 04
方法描述
方法描述
- 评分网络(Scoring Network):基于人类视频训练,预测场景评分C,决定是否需要重组环境或直接执行基础策略;使用时间衰减函数模拟人类重组过程的优先级
- 流生成网络(Flow Generation Network):使用CoTracker3从人类视频中提取物体点流(point flows),通过时空Transformer架构(DINOv2编码器)预测重组场景所需的点流
- 约简策略(Reduction Policy):将预测的点流转化为机器人可执行的动作原语(pick-and-place, push-and-pull, rotation三种类型),在任务无关的机器人play数据上训练
- 工作流程:评估当前观察→如果需要重组则执行约简策略→循环直到达到锚定状态→执行基础任务策略
Card 05
数据集与资源
数据集与资源
- 实验平台:Franka Emika机械臂,GELLO控制器遥操作,双摄像头设置
- 任务设置:4个真实世界任务(Pick-and-place, Reveal-and-pick, Rotate-and-place, Multi-task)
- 训练数据:
- 20个专家机器人演示(每个任务)
- 20个动作无关人类视频
- 20分钟任务无关机器人play数据
- 测试场景:每个任务15个测试场景,约80%为分布外状态
Card 06
评估与结果
评估与结果
- 评估指标:任务成功率
- 对比基线:ReSET Naive, Diffusion Policy, Dynamics-DP, π₀ (VLA)
- 主要结果:
- ReSET在所有四个任务上成功率最高
- 在不同数据量下(20-100个演示),ReSET均优于Diffusion Policy
- 扩散策略需要至少70个专家演示才能达到与ReSET相当 performance
- 约简策略能够有效处理长时域任务(如reveal-and-pick中的多步重组)
- 关键发现:基于流的约简策略比朴素匹配方法更灵活,能更好地适应物体位置的轻微变化