一眼看懂
封面预览
针对视觉-语言-动作(VLA)模型在长时序任务中推理效率低下的问题,提出一种KV-Efficient VLA方法,通过压缩KV缓存加速推理
- 针对视觉-语言-动作(VLA)模型在长时序任务中推理效率低下的问题,提出一种KV-Efficient VLA方法,通过压缩KV缓存加速推理
- 现有VLA模型(如OpenVLA 7B)推理速度仅约6 Hz,远低于实时机器人控制所需的50-100 Hz,且KV缓存随序列长度增长导致内存瓶颈
- 核心目标是在不修改下游控制逻辑的前提下,实现模型无关的内存压缩,提升推理速度和降低内存占用
Card 01
研究单位
研究单位
- University of Toronto(多伦多大学):Wanshun Xu, Long Zhuang
- Tsinghua University(清华大学):Lianlei Shan
Card 02
论文概述
论文概述
- 针对视觉-语言-动作(VLA)模型在长时序任务中推理效率低下的问题,提出一种KV-Efficient VLA方法,通过压缩KV缓存加速推理
- 现有VLA模型(如OpenVLA 7B)推理速度仅约6 Hz,远低于实时机器人控制所需的50-100 Hz,且KV缓存随序列长度增长导致内存瓶颈
- 核心目标是在不修改下游控制逻辑的前提下,实现模型无关的内存压缩,提升推理速度和降低内存占用
Card 03
核心贡献
核心贡献
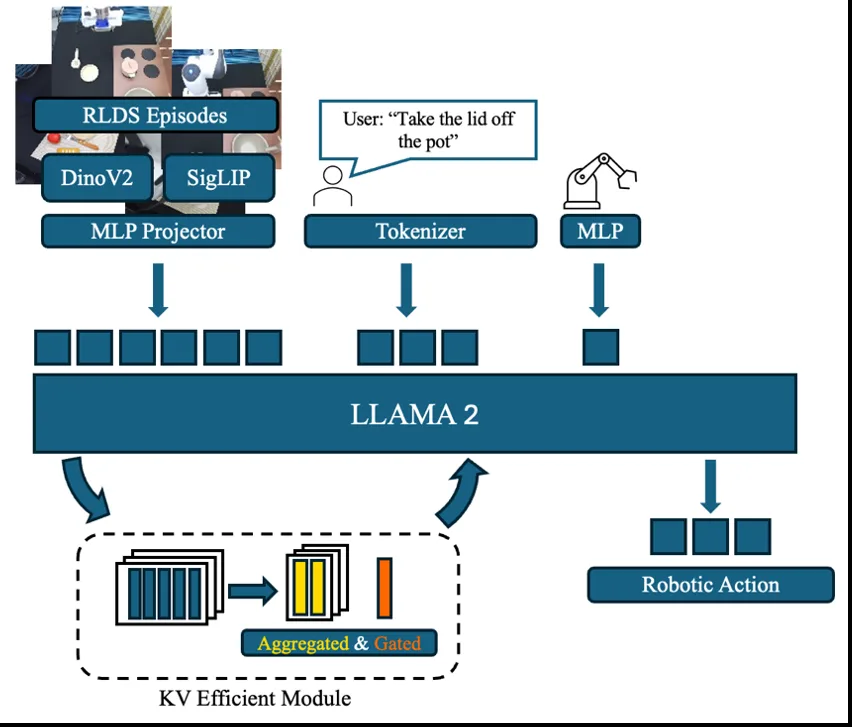
- 分块KV缓存策略(Chunked KV Strategy):将历史KV缓存分割为固定大小的块,通过MLP聚合压缩,减少全序列缓存的存储开销
- LSTM门控机制(LSTM Gating Mechanism):利用LSTM模块评估各聚合块的重要性,动态决定保留或丢弃,实现选择性上下文保留
- 理论计算效率分析:量化证明该方法在注意力计算中的FLOPs节省和内存压缩比,为长序列推理提供可扩展方案
- 模型无关的即插即用设计:可无缝集成到OpenVLA、CogACT、HybridVLA等现有VLA架构,无需修改下游控制逻辑
Card 04
方法描述
方法描述
- KV缓存分块与聚合:将KV缓存按固定长度C分块,使用2层MLP将每块聚合为单个(K̄, V̄)表示
- 循环门控选择:LSTM模块处理聚合后的块序列,输出保留分数s_t∈[0,1],基于可学习阈值τ决定是否保留该块
- 近期窗口保护:保留最近W个token的原始未压缩形式,确保细粒度信息的完整性
- 高效注意力计算:注意力仅在未压缩的近期窗口和保留的压缩块上进行,有效序列长度从n降至n'=W+M≪n
- 微调适配:采用LoRA低秩适配对预训练LLaMA-2 7B进行微调,补偿近似误差
Card 05
数据集与资源
数据集与资源
- 数据集:Open X-Embodiment(超过50万条演示,涵盖22种机器人本体和500+任务)
- 仿真环境:RLBench(基于CoppeliaSim,100+任务,约10万条轨迹)
- 基础模型:LLaMA-2 7B(隐藏维度4096,32层,32注意力头,GQA 8 KV头)
- 视觉编码器:DINOv2 + SigLIP ViT-Large(224×224分辨率)
- 训练框架:LLaMA Factory,混合精度训练
- 硬件资源:2× NVIDIA H800 GPU
Card 06
评估与结果
评估与结果
- 理论分析:在序列长度n≈20,000时,注意力FLOPs从1.49T降至0.41T,理论加速比1.61×,内存压缩比2.44×
- 推理速度:OpenVLA-KV-Efficient达7.6 Hz(1.22×),CogACT-KV-Efficient达13.8 Hz(1.33×),HybridVLA-KV-Efficient达8.3 Hz(1.47×),平均加速1.34×
- 计算效率:平均FLOPs节省24.6%,总FLOPs从2.37-2.73T降至1.81-1.94T
- 内存效率:KV缓存内存减少1.87×
- 训练稳定性:损失曲线在前100次迭代下降后稳定收敛,表明与HybridVLA训练动态兼容