一眼看懂
封面预览
针对自动驾驶系统在长尾场景(long-tail scenarios)中性能不足的问题,提出了一种持续学习的端到端自动驾驶框架
- 针对自动驾驶系统在长尾场景(long-tail scenarios)中性能不足的问题,提出了一种持续学习的端到端自动驾驶框架
- 通过Collect-and-Refine双阶段流程,结合视觉-语言-动作(VLA)模型和人在回路(HITL)测试,提升模型在安全关键场景下的决…
- 解决的核心问题:长尾场景高质量QA数据稀缺、稀疏数据下微调效率低下
Card 01
研究单位
研究单位
- 同济大学 交通运输学院(S. Fang 所属单位)
Card 02
论文概述
论文概述
- 针对自动驾驶系统在长尾场景(long-tail scenarios)中性能不足的问题,提出了一种持续学习的端到端自动驾驶框架
- 通过Collect-and-Refine双阶段流程,结合视觉-语言-动作(VLA)模型和人在回路(HITL)测试,提升模型在安全关键场景下的决策能力
- 解决的核心问题:长尾场景高质量QA数据稀缺、稀疏数据下微调效率低下
Card 03
核心贡献
核心贡献
- 构建了CAVE仿真平台,实现沉浸式人在回路测试,收集视觉 grounded 的接管数据
- 引入DPO(Direct Preference Optimization)方法,从稀疏接管数据中高效精炼行为,避免奖励黑客问题
- 在Bench2Drive基准上取得SOTA性能,Driving Score达72.18,Success Rate达50%
- 验证了模型通过持续学习避免重复失败、实现跨场景泛化的能力
- 建立了从HITL数据收集到行为精炼的完整技术 pipeline
Card 04
方法描述
方法描述
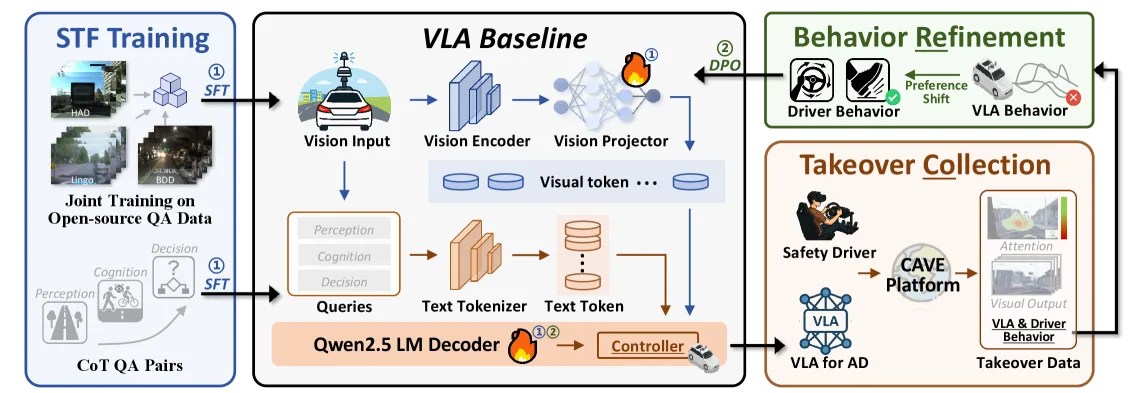
- 基于Qwen2.5-VL-7B模型,采用LoRA进行参数高效微调
- Pre-Stage 1:整合LingoQA、BDD、HAD等开源数据集进行SFT,构建70GB领域特定数据集
- Stage 1:在CAVE平台部署模型,通过VR头显让安全驾驶员在长尾失败场景中进行接管,收集偏好数据
- Stage 2:利用DPO对比模型生成的次优行为与人类接管行为,直接学习人类偏好,配合KL正则化防止策略漂移
- 采用Chain-of-Thought格式组织QA数据,增强可解释性和行为合理性
Card 05
数据集与资源
数据集与资源
- 数据集:LingoQA、BDD、HAD(整合为70GB QA数据集);CAVE平台采集的接管数据
- 基础模型:Qwen2.5-VL-7B(70亿参数视觉-语言模型)
- 微调方法:LoRA(应用于vision projector和LLM backbone)
- 仿真平台:自研CAVE(Cave Automatic Virtual Environment)沉浸式仿真环境
Card 06
评估与结果
评估与结果
- 开环评估:在LingoQA、BDD、HAD三个数据集上进行QA任务,使用BLEU、ROUGE-1、ROUGE-L指标,CoReVLA全面超越Qwen2.5-VL-7B、Llava-7B、LlavaNext-7B、Impromptu等基线
- 闭环评估:在Bench2Drive基准上进行,包含多样化长尾安全关键场景
- 关键指标:Driving Score(DS)、Success Rate(SR)、Efficiency、Comfortness
- 核心结果:DS 72.18(+7.96 vs SOTA),SR 50%(+15% vs SOTA);精炼后相比精炼前提升DS 18.92、SR 30%
- 案例研究:验证了从CAVE采集的接管经验可有效泛化到Bench2Drive的相似场景