一眼看懂
封面预览
提出 GeoAware-VLA,一种增强视觉-语言-动作模型对未见过相机视角泛化能力的方法
- 提出 GeoAware-VLA,一种增强视觉-语言-动作模型对未见过相机视角泛化能力的方法
- 核心问题:现有 VLA 模型难以从 2D 图像推断鲁棒的 3D 几何,导致在相机视角变化时性能急剧下降
- 目标:通过集成强几何先验,实现零样本视角泛化,同时保持分布内性能
Card 01
研究单位
研究单位
- Mohamed bin Zayed University of Artificial Intelligence(穆罕默德·本·扎耶德人工智能大学),机器人系,阿联酋阿布扎比
Card 02
论文概述
论文概述
- 提出 GeoAware-VLA,一种增强视觉-语言-动作模型对未见过相机视角泛化能力的方法
- 核心问题:现有 VLA 模型难以从 2D 图像推断鲁棒的 3D 几何,导致在相机视角变化时性能急剧下降
- 目标:通过集成强几何先验,实现零样本视角泛化,同时保持分布内性能
Card 03
核心贡献
核心贡献
- 提出将预训练几何基础模型 VGGT 作为冻结视觉编码器,通过轻量级可训练投影层适配到策略解码器
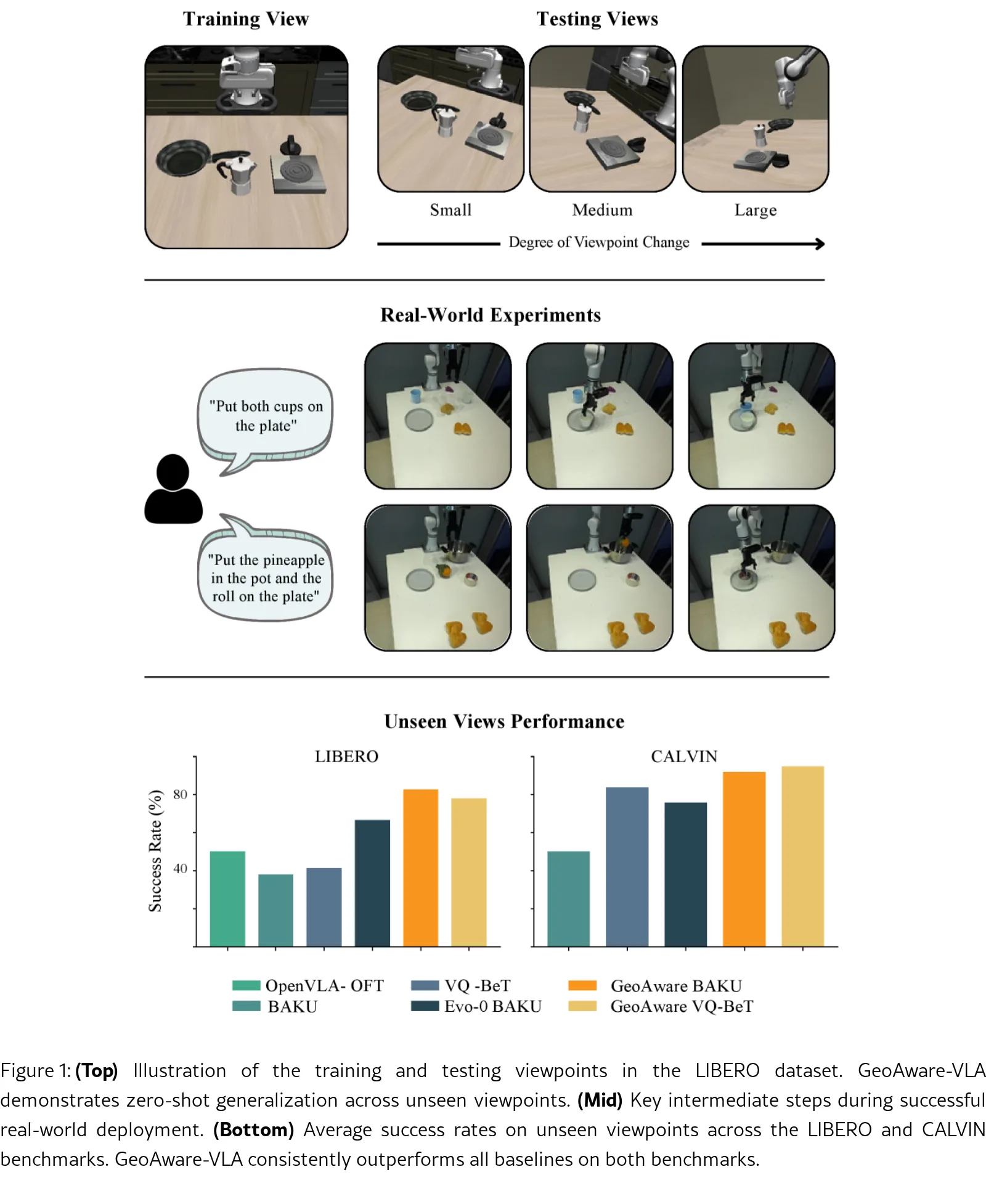
- 在 LIBERO 和 CALVIN 基准上实现显著的零样本视角泛化提升:LIBERO 未见过视角成功率平均提升 35 个百分点,CALVIN 提升 11 个百分点
- 证明方法对动作解码器选择具有鲁棒性,在连续动作空间(MLP Head)和离散动作空间(VQ-BeT Head)均有效
- 成功将模拟环境中的性能增益迁移到真实机器人平台
Card 04
方法描述
方法描述
- 几何感知视觉编码器:使用冻结的 VGGT(Visual Geometry Grounded Transformer)提取多尺度几何特征,替代传统可训练视觉编码器
- 多尺度特征投影:从 VGGT 的 24 层中选择 4 个均匀分布的中间层,通过 1D 卷积网络、自适应平均池化和 MLP 将特征映射到策略表示空间
- 策略架构:基于 BAKU 的 GPT 风格解码器-仅 Transformer,处理视觉、语言和本体感觉三种模态的嵌入
- 双动作头设计:支持 MLP Head(确定性连续动作)和 VQ-BeT Head(向量量化行为变换器,处理多模态动作分布)
Card 05
数据集与资源
数据集与资源
- LIBERO 基准:四个任务套件(Spatial、Object、Goal、Long),每任务 50 条演示
- CALVIN 基准:环境 D,8 个任务,每任务 50 条演示
- 真实世界实验:Realman 65B 机械臂,5 个桌面操作任务,每任务 50 条 VR 遥操作演示
- 训练资源:单张 NVIDIA A100 GPU(40GB VRAM),批量大小 64
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO 原始视角 + 3 个未见过视角;CALVIN 原始视角 + 4 个未见过视角;真实世界训练视角 + 零样本测试视角
- 主要指标:任务成功率(%)
- 关键结果:
- LIBERO 未见过视角平均成功率:GeoAware BAKU 82.6% vs BAKU 37.9% vs Evo-0 BAKU 66.6%
- CALVIN 未见过视角平均成功率:GeoAware VQ-BeT 94.8% vs VQ-BeT 83.8%
- 真实世界:GeoAware BAKU 在 5 个任务上均优于 BAKU 基线
- 特征分析:GeoAware-VLA 的跨视角余弦相似度达 0.91,显著高于 BAKU(0.77)和 Evo-0(0.69)