一眼看懂
封面预览
针对视觉-语言-动作(VLA)策略在跨机器人配置泛化方面的局限性,提出具身等变(Embodiment Equivariant)理论框架
- 针对视觉-语言-动作(VLA)策略在跨机器人配置泛化方面的局限性,提出具身等变(Embodiment Equivariant)理论框架
- 通过设计对机器人配置变换具有等变性的策略,实现跨具身预训练,使策略能够零样本泛化到新机器人配置,减少适应成本
- 解决现有VLA方法过度关注模型规模、数据集规模而忽视动作空间设计,导致配置泛化能力差的问题
Card 01
研究单位
研究单位
- 论文作者:Anzhe Chen, Yifei Yang, Zhenjie Zhu, Kechun Xu, Zhongxiang Zhou, Rong Xiong, Yue Wang
- 所属机构信息未在提供的HTML片段中明确标注
Card 02
论文概述
论文概述
- 针对视觉-语言-动作(VLA)策略在跨机器人配置泛化方面的局限性,提出具身等变(Embodiment Equivariant)理论框架
- 通过设计对机器人配置变换具有等变性的策略,实现跨具身预训练,使策略能够零样本泛化到新机器人配置,减少适应成本
- 解决现有VLA方法过度关注模型规模、数据集规模而忽视动作空间设计,导致配置泛化能力差的问题
Card 03
核心贡献
核心贡献
- 建立策略等变理论,统一跨具身的动作空间设计
- 设计等变动作解码器,对机器人配置变换具有等变性
- 提出几何感知网络架构,增强等变策略内的空间推理能力
- 在仿真和真实环境中验证预训练有效性和高效微调能力
Card 04
方法描述
方法描述
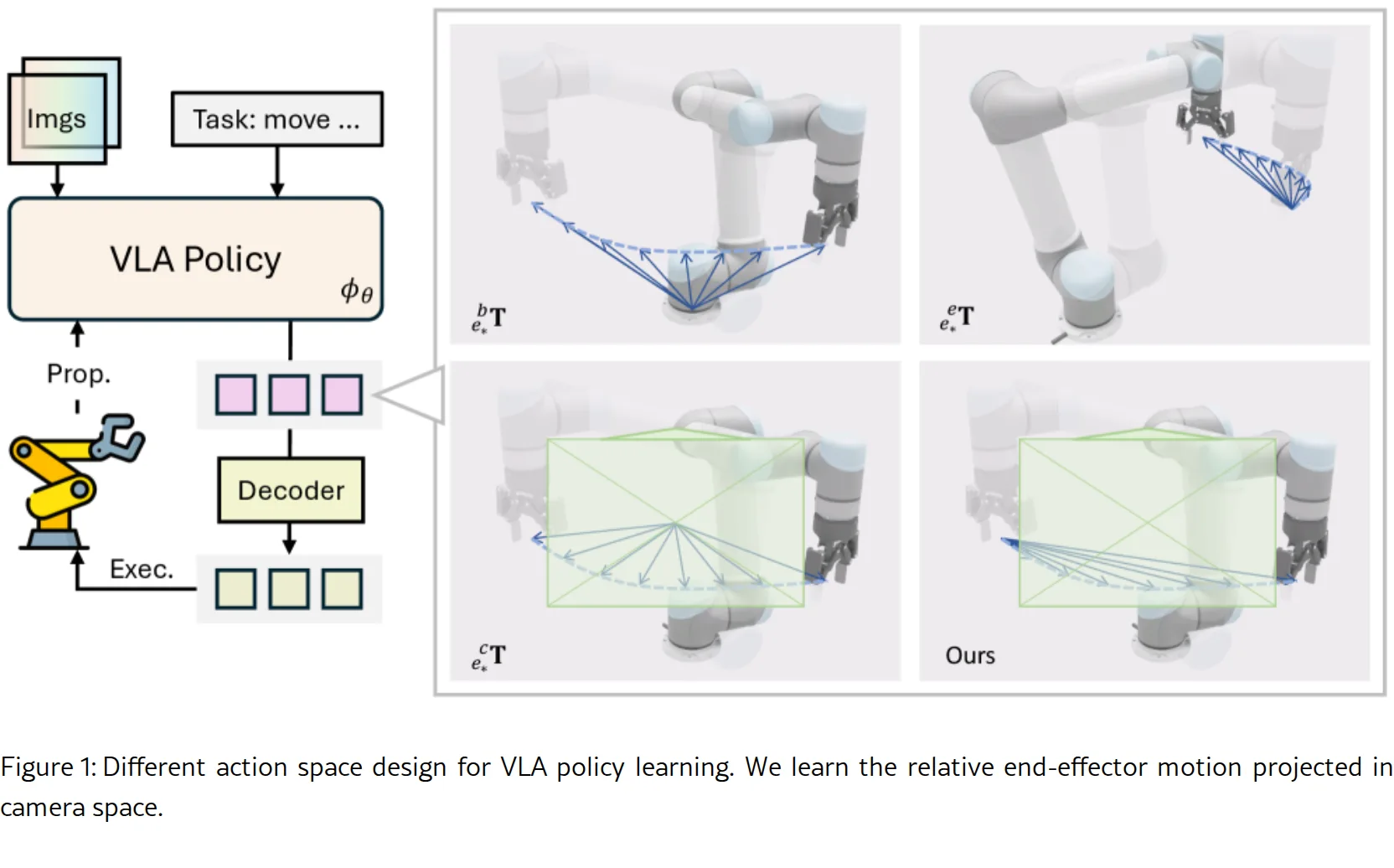
- 将策略分解为学习-based策略φθ(对配置变换不变)和分析解码器D(对配置变换等变)
- 采用相机空间中的相对末端执行器运动作为动作表示,实现配置等变性
- 引入相对相机位姿嵌入,通过旋转位置编码将几何信息注入注意力机制
- 设计修订版解码器Dr,在保持等变性的同时提高对相机标定误差的鲁棒性
Card 05
数据集与资源
数据集与资源
- 仿真实验使用LIBERO基准
- 真实世界实验包括Pick-Place任务和Table Storage任务
- 代码开源地址:https://github.com/hhcaz/e2vla
Card 06
评估与结果
评估与结果
- 在LIBERO基准上评估性能,与现有方法对比
- 进行不同动作空间设计的消融实验
- 验证零样本/少样本迁移到新机器人配置的能力
- 在真实机器人上验证Pick-Place和Table Storage任务