一眼看懂
封面预览
论文提出 SQAP-VLA,首个结构化、免训练的视觉-语言-动作(VLA)模型推理加速框架,同时实现最先进的量化和Token剪枝
- 论文提出 SQAP-VLA,首个结构化、免训练的视觉-语言-动作(VLA)模型推理加速框架,同时实现最先进的量化和Token剪枝
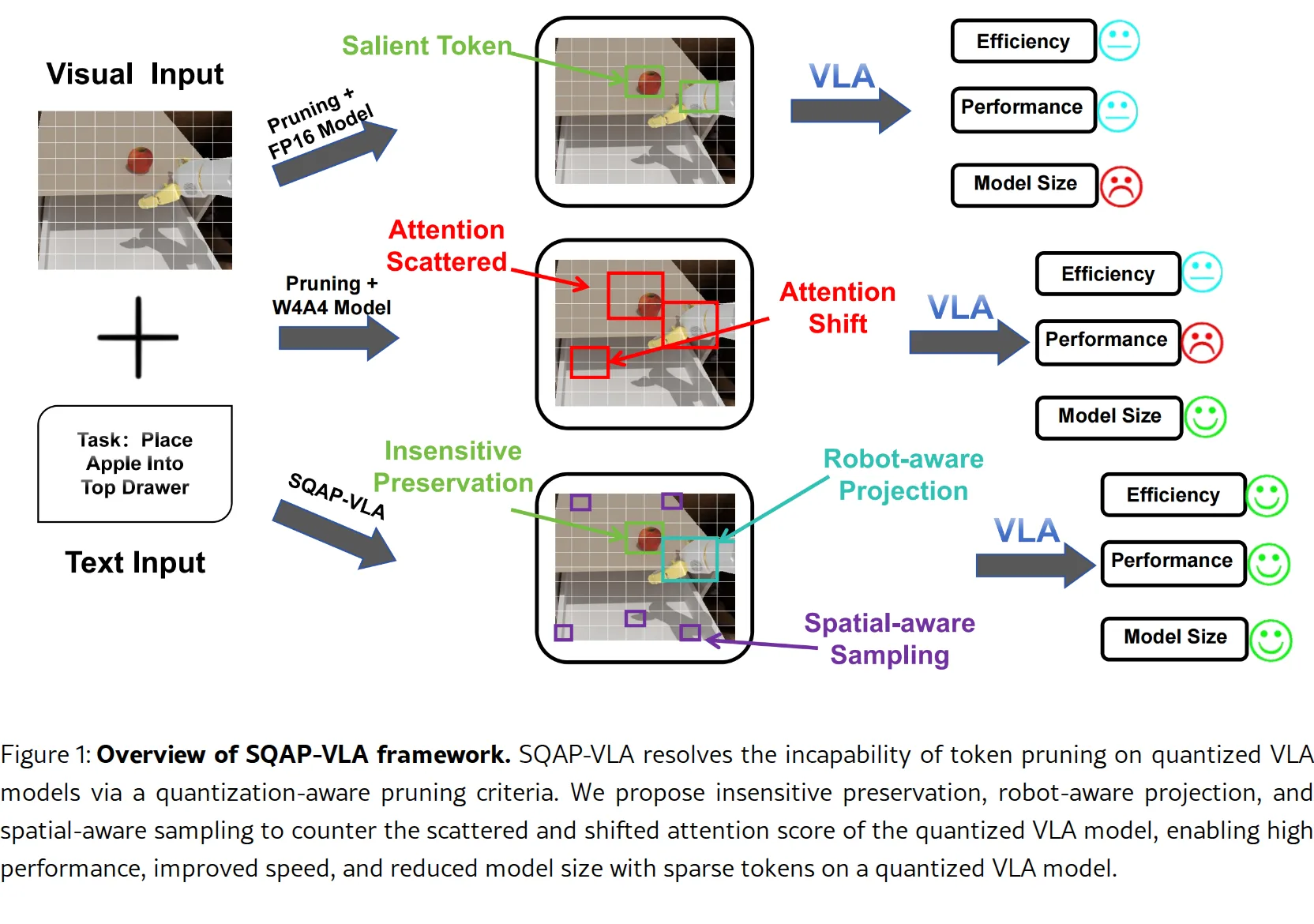
- 解决量化与Token剪枝之间的内在不兼容性问题:量化会扭曲注意力分布,导致传统剪枝策略失效;而剪枝后的有限信息使模型对量化更敏感
- 目标是在资源受限的边缘设备上实现高性能VLA模型的高效部署
Card 01
研究单位
研究单位
- Nanjing University (School of Electronic Science and Engineering): Hengyu Fang, Yijiang Liu, Yuan Du, Li Du
- University of Arizona: Huanrui Yang
Card 02
论文概述
论文概述
- 论文提出 SQAP-VLA,首个结构化、免训练的视觉-语言-动作(VLA)模型推理加速框架,同时实现最先进的量化和Token剪枝
- 解决量化与Token剪枝之间的内在不兼容性问题:量化会扭曲注意力分布,导致传统剪枝策略失效;而剪枝后的有限信息使模型对量化更敏感
- 目标是在资源受限的边缘设备上实现高性能VLA模型的高效部署
Card 03
核心贡献
核心贡献
- 首次识别并解决VLA模型中量化与Token剪枝的内在不兼容性问题,提出量化感知的协同设计框架
- 提出三种量化感知剪枝策略:量化不敏感Token保留(基于极端注意力分数的稳定性)、机器人感知Token保护(利用机械臂3D世界坐标投影)、空间感知Token采样(最远点采样保证空间覆盖)
- 提出面向剪枝的量词增强技术:结合Hadamard变换与张量级量化,平滑激活分布以提升注意力图可靠性
- 实现免训练的后训练压缩,无需昂贵的重训练或微调
- 在保持甚至超越原始模型性能的同时,实现1.93倍加速和73%以上的GPU内存降低
Card 04
方法描述
方法描述
- 量化感知剪枝策略:通过top-k选择保留量化不敏感的高注意力Token;利用相机内外参矩阵将机械臂3D坐标投影到2D像素坐标并映射为Token索引,形成保护环;对剩余Token使用最远点采样(FPS)保证空间多样性
- 剪枝目标量词增强:对Query和Key层的权重与激活应用Hadamard变换,将离群值能量均匀重分布到所有通道,结合通道级量化提升量化保真度
- 协同设计:量化与剪枝相互增强——剪枝策略适应量化后的特征分布,量化设计优化以支持更可靠的剪枝标准
Card 05
数据集与资源
数据集与资源
- 模型:CogAct(基于Prism-DinoSigLIP-224px视觉编码器、大语言模型和扩散动作头的VLA模型)
- 数据集:预训练于Open X-Embodiment (OXE) 大规模机器人学习数据集
- 量化配置:W4A4(4-bit权重和4-bit激活)
- 剪枝比例:0.4(即保留60% Token)
- 硬件:单张 NVIDIA RTX 3090 GPU 进行效率基准测试
Card 06
评估与结果
评估与结果
- 评估环境:标准机器人仿真基准(Simpler simulator)
- 任务:Pick Coke Can、Move Near、Open/Close Drawer、Place Apple in Top Drawer 四个代表性操作任务
- 评估指标:成功率(Success Rate, %)和加速比(Speed-up)
- 关键结果:
- Visual Matching场景:平均成功率79.3%,超越FP16基线(74.8%)4.5%,超越EfficientVLA(76.4%)2.9%
- Variant Aggregation场景:平均成功率64.4%,超越FP16基线(61.3%)3.1%
- 端到端系统加速1.93倍,LLM主干加速2.56倍(量化贡献2.09倍,剪枝贡献1.21倍)
- 峰值GPU内存从14.3GB降至7.6GB(降低46.9%),BOPs降至26.3%