一眼看懂
封面预览
论文提出 FLOWER(Florence With Embodied Flow),一种高效的视觉-语言-动作(VLA)策略模型,旨在解决现有…
- 论文提出 FLOWER(Florence With Embodied Flow),一种高效的视觉-语言-动作(VLA)策略模型,旨在解决现有…
- 核心目标是在保持竞争力的性能的同时,显著降低模型规模(<1B 参数)和训练成本(200 GPU 小时),实现"民主化"的通用机器人策略
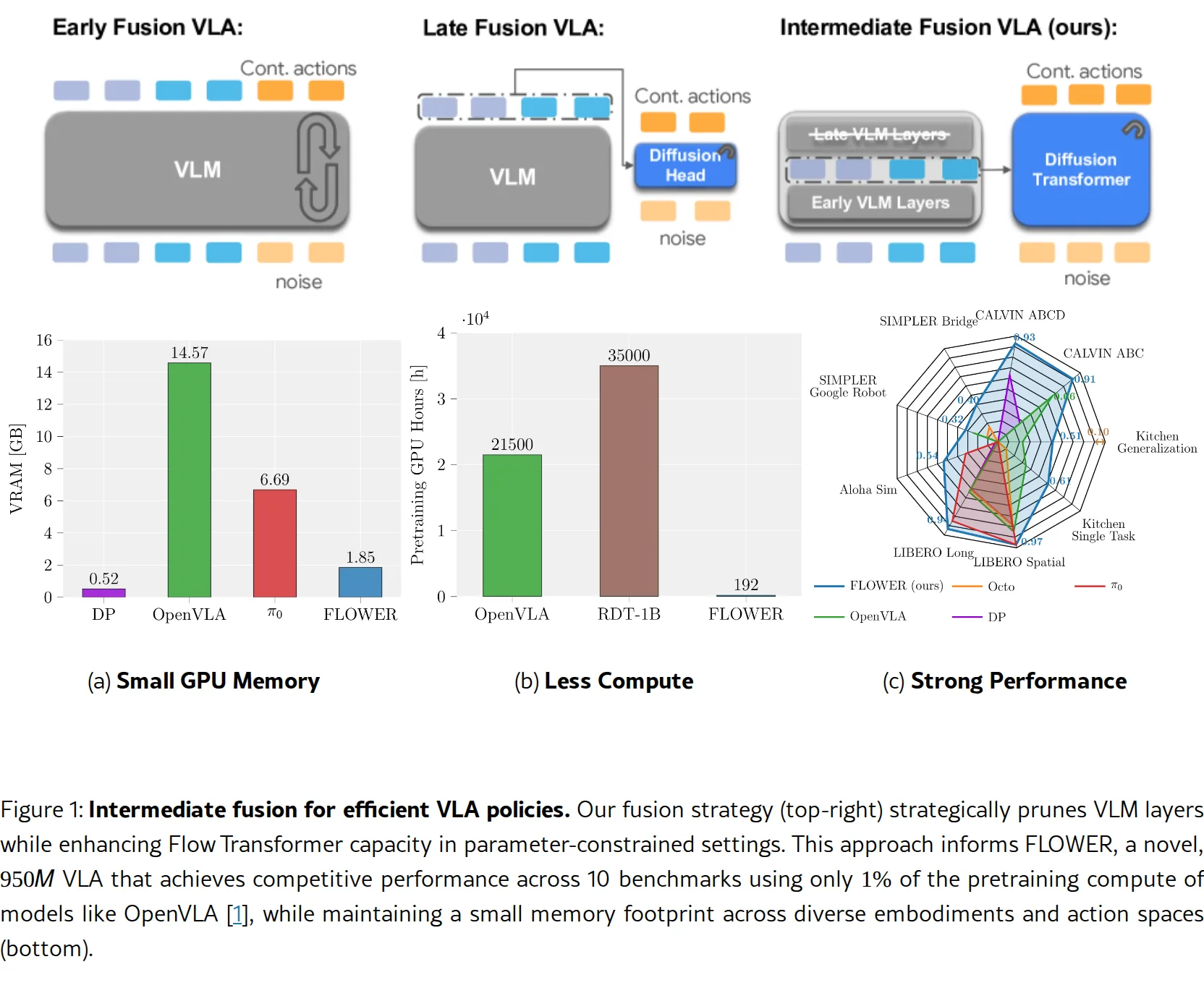
- 中间层模态融合(Intermediate Modality Fusion):通过剪枝 30-50% 的 VLM 层,将容量重新分配给扩散头,在…
Card 01
研究单位
研究单位
- Intuitive Robots Lab, Karlsruhe Institute of Technology, Germany(主要研究机构)
- Microsoft Research(合作机构,Fabian Otto 所属)
Card 02
论文概述
论文概述
- 论文提出 FLOWER(Florence With Embodied Flow),一种高效的视觉-语言-动作(VLA)策略模型,旨在解决现有 VLA 模型(如 OpenVLA、RDT-1B)参数量过大(数十亿参数)、训练成本高昂(数千 GPU 小时)的问题
- 核心目标是在保持竞争力的性能的同时,显著降低模型规模(<1B 参数)和训练成本(200 GPU 小时),实现"民主化"的通用机器人策略
Card 03
核心贡献
核心贡献
- 中间层模态融合(Intermediate Modality Fusion):通过剪枝 30-50% 的 VLM 层,将容量重新分配给扩散头,在保留语义理解的同时提升计算效率
- 全局动作空间 AdaLN(Global-AdaLN):提出动作特定的层归一化控制机制,通过模块化适配减少 20% 的参数量,且不损失准确性
- Rectified Flow 动作生成:采用直线流模型进行动作生成,仅需 4-8 步去噪,显著降低推理延迟
- 高效预训练策略:仅使用 250k 轨迹的精选"OXE-soup"数据集,在 200 H100 GPU 小时内完成预训练
- 跨具身泛化能力:统一处理单臂/双臂、delta-EEF/关节角度等多种动作空间,在 10 个基准测试的 190 个任务上验证
Card 04
方法描述
方法描述
- 架构设计:基于 Florence-2-L VLM 骨干网络(编码器-解码器架构),剪枝 50% 层数后保留编码器部分;搭配 18 层 Flow Transformer(1024 维隐层)
- 融合策略:在中间层提取 VLM 隐藏状态,通过线性投影和 RMSNorm 后,以交叉注意力注入 Flow Transformer
- 归一化创新:Global-AdaLN-Zero 在所有层共享调制权重,结合轻量级 LoRA 适配器实现层特定调制,替代标准 AdaLN 减少 20% 参数
- 训练目标:使用 Rectified Flow 学习从噪声到动作分布的速度场,优化条件流匹配损失
Card 05
数据集与资源
数据集与资源
- 预训练数据:8 个公开机器人数据集混合(约 250k 轨迹),包括 Droid、BridgeV2、Google Robot 等,75% 来自多样化环境数据
- 微调数据:Franka Panda 真实厨房环境 417 条轨迹(45 分钟演示)
- 模型规模:947M 参数(ViT 360M + VLM 205M + Flow Transformer 339M + 其他 43M)
- 训练资源:4× H100 GPU,48 小时(约 200 GPU 小时),BF-16 精度
- 推理资源:仅需 1.85 GB VRAM,RTX 4090 上可达 311 Hz 吞吐量
Card 06
评估与结果
评估与结果
- 仿真基准:CALVIN(ABC 设置新 SOTA 4.53 平均序列长度)、LIBERO(Long/Spatial/Object/Goal/90)、SIMPLER(Bridge/Google Robot)、Aloha 仿真
- 真实世界:Franka Panda 厨房 20 项任务,以及新颖物体、光照变化、背景干扰、新任务组合等泛化测试
- 关键结果:
- CALVIN ABC 平均序列长度 4.53,超越 OpenVLA(3.0)和 π₀(4.0)
- 真实世界任务成功率 61%,是 OpenVLA(31%)的两倍
- 泛化测试平均成功率 51%,远超 OpenVLA(23.4%)
- 推理速度比 OpenVLA 快 50 倍,内存占用仅 12.7%